Inhaltsverzeichnis
Kurze Einführung
Weißt Du genau, welche Issues-Typen Du in Deinem Issue Tracker verwenden sollst und wann welche? Weiß jeder in Deinem Projekt über Deinen Ansatz Bescheid? Werden Issue-Typen in Deinem Projekt immer konsistent verwendet? Solltest Du Technische User Stories verwenden oder nicht? Verwendest Du überhaupt Issue-Typen? Ist es für Dich nachvollziehbar, dass verschiedene Issue-Tracker so unterschiedliche Standard-Issue-Typen anbieten? Hast Du überhaupt schon einmal über Issue-Typen nachgedacht?
Wenn Deine Antwort auf eine oder mehrere der obigen Fragen “nein” oder “weiß nicht” oder “ist mir egal” lautet, bist Du nicht allein, und dieser Beitrag könnte für Dich interessant sein. Er enthüllt das Chaos hinter der oft sinnlosen, unsicheren und inkonsistenten Verwendung von Issue-Typen in vielen Software-Projekten. Er zeigt, warum eine bewusste und zielgerichtete Verwendung von Issue-Typen zu einer besseren Code-Verständlichkeit und Entscheidungsfindung sowie zu einem besseren Qualitäts-Monitoring in Projekten führen kann. Ich werde einen minimalen Satz an vernünftigen Issue-Typen zusammen mit verständlichen Regeln für ihre Verwendung vorschlagen. Insbesondere begründe ich, warum ein separater Issue-Typ zur Handhabung von technischen Schulden notwendig ist.
Wenn Du an Zusammenfassungen glaubst oder nur wenig Zeit hast, aber den Empfehlungen hier folgen und sehen möchtest, was passiert, dann springe einfach zum Abschnitt Minimaler Satz benötigter Issue-Typen und konfiguriere Deinen Issue-Tracker entsprechend. Wenn Du jedoch bereit bist, die ganze Geschichte zu hören, kannst Du die Reise gleich hier beginnen.
Bemerkung: Ich kenne den Unterschied zwischen “Refactoring” und “Re-Engineering”. Der Einfachheit halber werde ich jedoch den Begriff “Refactoring” als Oberbegriff für beide verwenden.
Schlechter Stand der Technik – Anarchie der Issues
In unseren Beratungsprojekten zur Software-Qualität finden wir oft eine ähnliche Situation vor: Weder Entwickler noch Architekten oder verantwortliche Projektleiter haben eine klare Vorstellung davon, wie viel Aufwand für Feature-Implementierungen, fürs Bug-Fixing oder für Refactorings im Projekt betrieben wird. Folglich wird es für sie beinahe unmöglich, die Auswirkungen von Verbesserungsaktivitäten zuverlässig zu messen und mit technischen Schulden effizient umzugehen. Es besteht oft große Unsicherheit hinsichtlich des Sinns und Nutzens von Refactorings, die in der Vergangenheit durchgeführt wurden. Wenn wir fragen, ob solche Verbesserungen den Feature-Durchsatz erhöht oder die Anzahl der Bugs oder den Wartungsaufwand verringert haben, sind die Antworten oft sehr vage. Informationen basieren hauptsächlich nur auf dem Bauchgefühl und den Erinnerungen von Personen, die zufällig an den entsprechenden Aktivitäten beteiligt waren.
In einigen Fällen sind sich die Projektbeteiligten nicht einmal sicher, welche Entitäten in ihren Issue-Trackern (oder Projektmanagement-Tools) Produkt-Features repräsentieren. In anderen Fällen sind sich die Entwickler nicht sicher, was sie als Fehler betrachten sollen: nur Fehler, die bei Kunden auftauchen, oder auch interne Probleme, die sie selbst oder ihre Kollegen entdeckt haben. Die Wahrheit ist jedoch, dass in fast allen Projekten architektonische Verbesserungen überhaupt nicht erfasst werden. Im besten Fall werden sie in Besprechungen mit Entscheidungsträgern diskutiert und nur spärlich in Wikis oder anderen unstrukturierten Dokumenten festgehalten. Meistens befindet sich solches Wissen jedoch nur in den Köpfen von Entwicklern. Entsprechende Arbeiten werden nicht in Issue-Trackern erfasst und sind in Commits oft nicht explizit sichtbar, als wären sie nicht Teil des Entwicklungsprozesses.
Dieser Mangel an strukturierten Informationen über wichtige Entwicklungsaktivitäten macht es schwierig, die richtigen Entscheidungen darüber zu treffen, wie das Projektbudget geplant und ausgegeben werden soll. Und führt letztlich zu einer Verschlechterung der Softwarequalität im Allgemeinen.
Unseren Beobachtungen zufolge liegt einer der Gründe für diese Situation in der Unsicherheit hinsichtlich der korrekten und konsistenten Verwendung von Issue-Trackern und Issue-Typen. Es werden dafür leider keine allgemein verständlichen und pragmatischen Regeln aufgestellt.
Dieser Beitrag ist ein Versuch, solche Regeln zu identifizieren.
Standard-Issue-Typen in Issue-Trackern
Wenn man sich die Standard-Issue-Typen der populären Issue Tracker (wie in der Tabelle unten skizziert) ansieht, wird man feststellen, dass es eine beträchtliche Vielfalt an Typen für funktionale Ausgaben gibt. Es geht dabei um Issues, welche Änderungen im Zusammenhang mit Produkt-Features, auch Business-Funktionalität genannt, darstellen. In Jira gibt es sogar vier solcher funktionsbezogenen Typen mit unterschiedlicher Granularität (Epic, New Feature, User Story und Improvement). Es gibt auch einige Variationen von Typen, die Arbeiten im Zusammenhang mit Fehlern repräsentieren. Normalerweise wird dieser Typ einfach “Bug” genannt. YouTrack stellt eine echte Ausnahme dar, indem es (im Ernst?!) drei verschiedene Fehlertypen vorschlägt: Bug, Cosmetic und Exception.
Standard Issue-Typen einiger populärer Issue-Tracker
| |
Jira |
You
Track |
Azure
Boards |
Trac |
Redmine |
| funktional |
Epic |
✘ |
|
✘ |
|
|
(New)
Feature |
✘ |
✘ |
✘ |
|
✘ |
| User Story |
✘ |
|
✘ |
|
|
| Improvement |
✘ |
|
|
|
|
| Enhancement |
|
|
|
✘ |
|
| Fehler |
Bug |
✘ |
✘ |
✘ |
|
✘ |
| Defect |
|
|
|
✘ |
|
| Cosmetic |
|
✘ |
|
|
|
| Exception |
|
✘ |
|
|
|
| Verschiedenes |
Task |
✘ |
✘ |
✘ |
✘ |
|
| Sub-Task |
✘ |
|
|
|
|
Allen populären Issue-Trackern ist jedoch gemeinsam, dass ihnen Issue-Typen für technische/architektonische Arbeiten fehlen. Als wäre es etwas, das keine Sichtbarkeit verdient. Zugegeben, Azure Boards mit seinem “Architectural” “Value Area”-Feld für User Stories ist eine gut gemeinte Ausnahme (aber auch nicht mehr!) – dazu später noch mehr (siehe Abschnitt Technische (User) Stories).
Du wirst jetzt denken: Halt – keine Typen für technische Arbeiten? Aber genau dafür sind doch Tasks da, oder? Nun, schauen wir mal.
Definitionen von “Task”
So wird eine Task von Atlassian in Jira definiert:
A task represents work that needs to be done
— Rachel Wright. Different Jira Issue Types [10]
Wenn Du glaubst, dass etwas bedeutungsloseres nicht möglich ist (mit Ausnahme von Issue-Typen für Arbeiten, die nicht getan werden müssen), kann ich noch einen drauflegen: Dies ist die Standardbeschreibung einer Tasks in der Jira Cloud-Benutzeroberfläche:
A task that needs do be done
— Jira UI Task description
Im Grunde sagt Jira also “eine Task ist eine Task”, was eine völlig redundante Aussage ist. Der Marktführer für Issue-Tracker sagt uns also nicht, wofür Tasks eigentlich da sind. Vielleicht können wir woanders eine nützlichere Definition finden:
Tasks can include development, testing, and other kinds of work
— Agile process work item types and workflow [11]
Nun, vielen Dank. Es ist sehr beruhigend zu wissen, dass eine Task in einem Software-Entwicklungsprojekt auch Entwicklungsarbeit enthalten kann. Als ob die anderen Issue-Typen nicht für die Entwicklung wären. Microsoft hat also auch keine klare Definition für eine Task- es ist wieder ein Schweizer Taschenmesser.
Könnte es sein, dass Tool-Anbieter nicht die richtigen Ansprechpartner sind, um nach solchen Definitionen zu suchen? Entsprechende Tools sollten schließlich bei jeder Art von Entwicklungsprozessen eingesetzt werden können, so dass Tool-Anbieter bewusst vage bleiben und es dem jeweiligen Projekt überlassen, den Issue-Typen Sinn zu verleihen?
Mal sehen, was Scrum zu Tasks zu sagen hat:
The product backlog items may be broken down into tasks by the development team
— Wikipedia. Scrum [20]
Interessant – Scrum sagt nichts über die Art der Arbeit aus, die eine Task darstellt. Es betrachtet Tasks lediglich als ein Mittel zur Zerlegung und Organisation der Arbeit um funktionale Issues herum.
Übrigens: im Scrum-Guide von Ken Schwaber und Jeff Sutherland [19] wird der Begriff “Task” überhaupt nicht erwähnt.
Allgemeine Verwendung von Tasks
Wie kommt es, dass Tasks trotz fehlender Klarheit über ihre Bedeutung im Allgemeinen mit technischer Arbeit in Verbindung gebracht werden? Ich glaube, es ist eine Kombination von zwei Aspekten:
Erstens: Egal wie man es dreht und wendet, jedes Software-Projekt erfordert technische Arbeiten. Und damit meine ich echte technische Arbeiten, die nicht mit einer bestimmten Funktionalität verbunden ist. Du hast es erraten: Ich spreche von architektonischen Verbesserungen, Refactorings, Re-Engineerings, oder übergreifenden infrastrukturellen Änderungen (wie z.B. die Umstellung auf ein neues Framework). Und da es für diese Art von Arbeit keine speziellen Issue-Typen gibt, werden einfach Tasks verwendet.
Zweitens: Bei der Zerlegung (Dekomposition) von User Stories oder Features in kleinere Teile können Issues entstehen, welche zufällig keine Benutzersichtbarkeit haben – solche Aufgaben werden dann ebenfalls als “technische” Arbeit angesehen.
Lasst mich erklären, was ich mit “zufällig” meine und warum die Tasks im zweiten Fall nicht wirklich technisch sind. Die Art und Weise, wie ein funktionales Issue in Tasks unterteilt wird, hängt von den Gewohnheiten, Fähigkeiten und dem persönlichen Geschmack der Teammitglieder ab – es gibt keine festen Regeln. Und das ist auch gut so, denn es gibt dem Team die Freiheit, die Arbeit auf seine eigene Weise zu organisieren.
Sehen wir uns als Beispiel zwei mögliche Task-Dekompositionen eines Features an, das es dem Benutzer erlaubt, ein Bild in sein Profil hochzuladen. Mit der Möglichkeit, einen Teilbereich des Bildes auszuwählen. Eine fein-granulare Zerlegung könnte folgendermaßen aussehen:
- Hinzufügen einer UI-Logik zur Auswahl der Bilddatei und zur Anzeige des hochgeladenen Bildes (d.h. “Upload”-Button + Widget zur Anzeige des Bildes)
- Hinzufügen einer UI-Logik zur Auswahl eines Bildbereichs
- Hinzufügen eines Web API zum Hochladen/Speichern des Bildes im Profil des Benutzers
- Erweitern des Backend-Datenmodells, so dass Bilder mit Benutzern assoziiert werden können
Dekomposition 1:
- Task 1.1: Frontend-Arbeit bestehend aus den Teilen 1 und 2
- Task 1.2: Backend-Arbeit bestehend aus den Teilen 3 und 4
Dekomposition 2:
- Task 2.1: Upload-Funktionalität bestehend aus den Teilen 1, 3 & 4
- Task 2.2: Funktionalität zur Auswahl einer Teilabschnitts, bestehdn aus Teil 2
Die klassische Frontend-Backend-Zerlegung führt zu einer Task mit und einer Task ohne Benutzersichtbarkeit. Folglich würde Task 1.2 gemeinhin als “technisch” angesehen werden. Die gleichermaßen legitime zweite Zerlegung kommt gänzlich ohne “technische” Aufgaben aus, da jede Task das Benutzerinterface beeinflusst (d.h. ein neues Verhalten beschreibt). Das ist seltsam, nicht wahr? Für dasselbe Feature erhalten wir unterschiedlich viel technische Aufgaben. Kann das wahr sein?
Nein, offensichtlich kann es nicht wahr sein. Diese Sichtweise auf Dekomposition ist grundsätzlich falsch. Aber nicht, weil eine der Dekompositionen richtig und die andere falsch ist, sondern weil dabei überhaupt keine echten technischen Aufgaben entstehen können. Die Backend-Arbeiten in Task 1.2, die gewöhnlich als “technisch” eingestuft werden, stellen kein ausgeprägtes technisches Anliegen des Systems dar. Sie stellen vielmehr lediglich ein organisatorisches Anliegen dar. Task 1.2 ist lediglich ein Ergebnis der Arbeitsteilung – diese ist unabhängig von Kategorien wie “funktional” und “technisch”. Die gesamte Arbeit im Zusammenhang mit der Implementierung einer bestimmten Funktionalität (Feature/User Story) sollte als funktional betrachtet werden. Es hat keinen Mehrwert, wie verrückt zwischen funktional und technisch auf dieser unteren Ebene zu unterscheiden. Insbesondere, weil es Verwirrung stiftet und die Grenzen zwischen echten technischen Belangen (die einen eigenen Issue-Type verdienen) und unterstützenden Teilaufgaben von übergeordneten funktionalen Issues, die nur scheinbar technisch sind, verwischt. Letzten Endes ist jede Programmierarbeit für sich genommen technisch. Die Feststellung, dass die Implementierung eines funktionalen Anliegens “technischen” Aufgaben impliziert ist also überflüssig.
Die Unsicherheit, welche sich aus dem Fehlen von Standard-Issue-Typen für technische Belange in populären Issue-Trackern ergibt sowie die unscharfe Bedeutung und ambivalente Verwendung von Tasks, führte zur Entstehung einer etwas seltsamen Entität namens Technical User Story (oder einfach nur Technical Story).
Technische (User) Stories
Im Grunde genommen stellen Technical User Stories nur einen bestimmten Issue-Typ (in einem Issue Trackers) dar, welcher für technische Arbeiten verwendet werden soll. Und als solche sind Technical User Stories in erster Linie ein gut gemeinter Versuch, technischen Anliegen in Software-Projekten die Sichtbarkeit zu verleihen, die sie verdienen (see z.B. “TECHNICAL USER STORIES – WHAT, WHEN, AND HOW?” von Robert Galen [9]).
Leider ist dieser Ansatz nicht mutig genug: der Begriff “Technical User Story” allein erscheint wie ein Versuch, technische Belange hinter funktionalen zu verstecken und ihnen damit die Bedeutung zu nehmen, die ihnen naturgemäß zukommt. Es ist schon erstaunlich: Wie kann es sein, dass Menschen die Ironie hinter dem Begriff nicht sehen? Wie ist man auf etwas so Widersprüchliches gekommen?
Ich glaube, die Geschichte geht ungefähr so: User Stories haben einen brillanten Ruf, sie werden von Scrum-Mastern, Product-Ownern, Managern, agilen Coaches und sogar Kunden geliebt. User Stories sind die Helden der wertorientierten Software-Entwicklung – sie allein schultern den gesamten Geschäftswert der Software. Und so muss sich jemand gedacht haben, was liegt denn näher, als technische Probleme unter dem vorzeigbaren Schleier der User Stories zu verstecken. Sie zu Bürgern erster Klassen in Product Backlogs und Sprints zu machen, nur indem man “User Story” mit dem Wort “technisch” verknüpft. Wird schon niemand merken.
Der Trick ist jedoch ziemlich durchsichtig. Folglich erkannten die Menschen recht bald, dass technische User Stories mit bestimmten Problemen behaftet sind. Zum Beispiel, weil es extrem frustrierend ist, technische Belange durch die Verwendung der klassischen “Als <Rolle>, möchte ich <Ziel> um <Nutzen>”-Vorlage auszudrücken. Entweder landet man bei Monstrositäten wie:
- “Als SYSTEM A möchte ich … um SYSTEM B …” (siehe hier [8])
- “Als ENTWICKLER möchte ich refaktorisieren, …”
- “Als TESTER, …”
oder Befürworter von technischen User Stories argumentieren, dass es in Ordnung ist, für technische User Stories auf die klassische User-Story-Formulierung zu verzichten. Und sie haben sicherlich Recht. Warum aber das Ganze dann als User Story bezeichnen? Technische Belange haben weder Endbenutzer noch bilden sie irgendwelche Geschichten – so einfach ist das
Zusätzlich tragen dieselben Befürworter zu noch größerer Verwirrung bei, indem sie alles in einen Topf werfen (wie hier [9] and hier [8]), wenn es um eine Definition von technischen User Stories geht. Sie schlagen vor, dass technische User Stories für alle folgende Belange verwendet werden können:
- Operational Requirements [4] (wie z.B. Performance-Verbesserungen) ODER
- Developmental Requirements [4] (wie technische Schulden und Refactorings) ODER SOGAR
- zur Beschreibung nicht-funktionaler Teil-Aspekte, bei der Implementierung von funktionalen User Stories unterstützen (z.B. Änderung technischer Infrastruktur durch Hinzufügen von DB-Tabellen usw.)
Das ist ziemlich verwirrend, und so fragen Menschen berechtigterweise nach dem Unterschied zwischen Technical User Stories und Tasks und stellen den Sinn von technischen User Stories in Frage. Aufgrund dieses undifferenzierten Ansatzes verursachen technische User Stories letztlich mehr Chaos und Unverständnis, als dass sie echte Probleme lösen.
Kommt schon, wir sind doch alle erwachsen. Es ist nicht möglich, den Ruf von technischen Belangen in Software-Projekten zu verbessern und ihre Akzeptanz bei Managern und Product-Ownern zu erhöhen, nur indem man sie als eine besondere Art von User Stories ausgibt. Das ist nicht nötig, denn es gibt echte Gründe, technische Issues (für technische Schulden, architektonische Verbesserungen, Refactorings usw.) als Bürger erster Klasse von Software-Projekten zu betrachten. Bevor ich zu diesem Punkt komme, lasst mich noch ein paar Worte über das allgemeine Chaos im Zusammenhang mit Issue-Type sagen.
Woher kommt das Chaos?
Im Allgemeinen werden Issue-Tracker in Software-Projekten nur als eine Art funktionsreiche To-Do-Liste betrachtet. Sie dienen dazu, den Überblick über laufende und zukünftige Aufgaben zu behalten und Zusammenarbeit zu ermöglichen. Unter solchen Umständen hat es in der Tat wenig Sinn, sich mit verschiedenen Typen von Issues zu befassen. Für denjenigen, der die Aufgaben erstellt oder bearbeitet, gibt es keinen nennenswerten Unterschied zwischen Bugs und Features oder anderen Arten von Issues – es gibt lediglich eine Liste von priorisierten Aufgaben, die erledigt werden müssen. Ein Bug ist nicht automatisch wichtiger als ein Feature und umgekehrt, und um “Wichtigkeit” auszudrücken, gibt es in Issue-Trackern andere Mittel als Issue-Typen. Das Gleiche gilt auch für die Dekomposition und Arbeitsteilung – man braucht nicht wirklich einen separaten Issue-Typ, wie z.B. Task oder Sub-Task, um Eltern-Kind-Beziehungen zwischen Issues auszudrücken – die Existenz entsprechender Verbindungen an sich reicht aus.
Folglich fühlen sich Menschen von der Anzahl der Standard-Issue-Typen oft überfordert, weil sie ihren Zweck nicht vollständig verstehen. Anstatt Issue-Typen zielgerichtet zu verwenden, haben sie mit Fragen wie den folgenden zu kämpfen:
- Sollte es eine User-Story oder ein Feature sein?
- Besteht ein Feature aus mehreren User Stories oder umgekehrt?
- Wann sollte man Epics verwenden?
- Was ist der Unterschied zwischen Task und Sub-Task?
- Was ist der Unterschied zwischen Task und Technical Story?
- Wozu sind Improvements/Enhancements gut?
- Muss / darf ich technische Belange als Issues erfassen?
- Was wird der Projektleiter von mir denken?
- Wann Ist die Kaffeepause?
Und weil es oft keine einzige Person im Projekt gibt, die solche Fragen konsistent beantworten kann, fängt man an, im Internet zu suchen, nur um herauszufinden, dass die einzig gültige Antwort darin besteht, dass
- es keine universelle Antwort gibt
- Issue-Typen das sind, was Du und Dein Team daraus machen
- und dergleichen mehr …
Kommt Dir das bekannt vor? Wenn nicht, wirf einfach einen Blick auf Diskussionen wie Feature vs Task vs Story [13] und Relationship between user story, feature, and epic? [14].
Das Ergebnis dieser ganzen Verwirrung ist, dass man die Erstellung von Issues auf ein Minimum reduziert, um keine Fehler zu machen. Bugs werden im Rahmen von funktionalen Issues nebenher behoben; Feature-Implementierungen werden durch kosmetische Änderungen verunreinigt, Refactorings verschwinden vollständig und so weiter. Und so verliert das Projekt wertvolle Informationen und wird durch schwer nachvollziehbare Code-Änderungen belastet.
Tag-basierte Issue-Tracker, wie sie in GitLab und GitHub verfügbar sind, entziehen sich dem Problem, indem sie das Konzept der Issue-Typen gar nicht implementieren. Und obwohl es in der Tat einige Mühsal bei der Wahl des richtigen Issue-Typs ersparen kann, führen solche Konzepte in der Regel nicht zu besser strukturierten und disziplinierten Vorgehensweisen in Projekten, die notwendig sind, um die volle Leistungsfähigkeit von Issue-Trackern zu nutzen.
Wie man es besser macht – mit Issue-Typen, die Sinn machen
Um den größtmöglichen Nutzen aus Issue-Trackern zu ziehen, müssen wir in ihnen mehr sehen als bloß To-Do-Listen.Sie haben mindestens zwei weitere Rollen.
Issue-Tracker als Coding-Tools
Inzwischen dürfte der überwiegenden Mehrheit der Entwickler und Projektleiter klar geworden sein, wie wichtig der korrekte Einsatz von Versionskontrollsystemen für die allgemeine Softwarequalität ist. Wie wichtig eine saubere und strukturierte Commit-Historie ist. Dass ein Commit nur eine einzige logische und zusammenhängende Änderung darstellen sollte (“atomare” Commits). Dass eine Commit-Message das Was und Warum eines Commits beschreiben sollte, um den Kontext einer Änderung wiederherzustellen. Dass das Vermischen nicht-zusammenhängender Änderungen den kognitiven Aufwand (= WTFs per minute [15]) erheblich erhöht, der erforderlich ist, um frühere Änderungen zu verstehen und Code erneut zu ändern. Und dass das Lesen und Verstehen (nicht das Schreiben) von Code das ist, was Entwickler die meiste Zeit tun:
Indeed, the ratio of time spent reading vs writing is well over 10:1
— Robert C. Martin. Clean Code [1].
Und dass die Reduzierung dieses Leseaufwands das ist, was für die Codequalität am meisten zählt.
Wenn Du das nicht weißt oder nicht glaubst, hast Du höchstwahrscheinlich schwerwiegendere Probleme als Issue-Typen in Deinem Projekt. Am besten wäre es, mit den Grundlagen zu beginnen, wie beispielsweise How to Write a Git Commit Message [16] oder DEVELOPER TIP: KEEP YOUR COMMITS “ATOMIC” [17] und später hierher zurückzukehren.
Warum erwähne ich Versionskontrollsysteme, wenn wir über Issue-Tracker sprechen? Weil beide im selben Team spielen und für die Verständlichkeit des Codes mitverantwortlich sind. Versionskontrollsysteme und Issue-Tracker gehören untrennbar zusammen, und sie werden buchstäblich miteinander verbunden, sobald man anfängt, Commits mit Issues zu verknüpfen – eine weitere Best Practice, die in jedem Projekt befolgt werden sollte.

Die Synergie von Versionskontrollsystemen und Issue-Trackern – auch Code Traceability genannt – führt zu einer ganzheitlichen Sichtweise in einem Projekt, bei der jede Codeänderung bis zu ihrem letztendlichen “Warum” – dem Issue – zurückverfolgt werden kann. Und jedes Issues identifiziert einen Satz von zusammenhängenden Codeänderungen.
Unter diesen Gesichtspunkten gelten für Issues die gleichen (Single Responsibility) Prinzipien wie für Commits:
- ein Issue sollte nur ein logisches und zusammenhängendes Anliegen darstellen
- das Mischen nicht-zusammenhängender Änderungen unter demselben Issue, erhöht wesentlich den kognitiven Aufwand zum Verstehen entsprechender Änderungen
Nichts ist so frustrierend und zeitraubend, wie der Versuch, ein Stück Code zu verstehen, das unter einem bestimmten Issue committed wurde, von der Logik her aber nicht zu diesem Issue gehört. Das Issue hinter einer Codeänderung repräsentiert deren Grund – es ist die ausdrücklich Erklärung dieser Änderung auf höchster Ebene. Als Entwickler neigen wir dazu, solche Erklärungen nicht anzuzweifeln. Wir versuchen die Änderung im Kontext einer solchen Erklärung zu verstehen. Wenn also jemand behauptet A zu machen, zusätzlich aber noch B und C macht, dann sabotiert er die Verständlichkeit von allem, was er macht. Nicht-zusammenhängende Änderungen unter demselben Issue zu vermischen, ist wie das absichtliche Einfügen falscher Kommentare im Code – es gibt kaum eine wirksamere Methode, den Sinn des Codes zu verschleiern.
Als Entwickler liegt es in unserer Verantwortung, sich stets über die konkreten Gründe für Codeänderungen im Klaren zu sein. Wir müssen in dieser Hinsicht absolut diszipliniert sein. Andernfalls tappen wir im Dunkeln und richten Chaos an. In diesem Zusammenhang sind Issue-Typen ein mächtiges Konzept, um die Gründe für Code-Änderungen auseinanderzuhalten. Sie schaffen ein mentales Modell in unseren Köpfen, das uns hilft, über die Kohärenz von Codeänderungen auf die richtige Art und Weise nachzudenken. Wenn es keinen Issue-Typ für Refactorings gibt, ist die Versuchung ziemlich groß, Feature-Implementierungen mit nicht-zusammenhängenden Code-Verbesserungen zu vermengen. Wenn es keinen Issue-Type für Fehler gibt, werden Bug-Fixes viel häufiger nebenher gemacht, und so weiter. Und all diese spontanen Änderungen werden es nicht nur schwierig machen, die Implementierung des eigentlichen Issues zu verstehen, sondern ihre eigenen Gründe werden auch weitgehend undokumentiert bleiben, weil sie nicht in separaten Issues zum Ausdruck kommen. Falls entsprechende Konzepte im Projekt fehlen, haben die Beteiligten schlichtweg keine Hinweise darauf, wie es richtig geht und werden somit auch nicht den Eindruck haben, etwas falsch zu machen.
Um es kurz zu machen: Codeänderungen haben Gründe. Und diese Gründe sind unterschiedlicher Art. Wenn diese Arten nicht explizit als Issue-Typen modelliert werden, erhöht sich die Wahrscheinlichkeit chaotischer Codeänderungen erheblich. Die Existenz von Issue-Typen zwingt uns zu bewussten Entscheidungen darüber, was wir tun. Solche Entscheidungen sind oft nicht trivial, aber sie sind notwendig, und sie zahlen sich aus. Tut mir leid, Kumpel, aber so ist es nun einmal.
Issue-Tracker als Grundlage für Qualitäts-Monitoring
Es ist viel darüber geschrieben worden, dass Softwarearchitekturen keine endgültigen Lösungen darstellen, sondern eher Lösungsansätze, die im Laufe des Projekts und bei neuen Anforderungen ständig angepasst werden müssen. “Architecture with Agility” by Kevlin Henney [3] ist ein großartiger Beitrag zu diesem Thema. Tom Gilb hat es jedoch auf den Punkt gebracht:
Architecture is a hypothesis, that needs to be proven by implementation and measurement.
— Tom Gilb
Im Grunde bedeutet das, dass sich Softwarearchitekturen innerhalb von Feedback-Schleifen entwickeln – das ist nichts Neues. Effiziente Feedback-Schleifen erfordern jedoch Wissen, um bestehende Probleme zu identifizieren, die Auswirkungen vergangener Maßnahmen einzuschätzen und Entscheidungen für die Zukunft zu treffen. In vielen Projekten basiert dieses Wissen zu einem großen Teil nur auf dem Bauchgefühl. Dies ist eine recht schwache Form der Messung. Wenn wir ehrlich sind, ist es überhaupt keine Messung. In diesem Zusammenhang können Issue-Tracker wertvolle Daten liefern, die für nützliche Messungen genutzt werden können.
Das “Verhalten” der Softwarearchitektur in Bezug auf Feature-Implementierungen ist der ultimative Maßstab für die Qualität dieser Architektur (um nur Tom Glib zu paraphrasieren). D.h., dass der Aufwand, der erforderlich ist, um neue Features in ein System mit einer “guten” Architektur einzuführen, ungefähr proportional nur zur Komplexität der Features und nicht zur Komplexität des gesamten Systems ist.
Um es in einfachen Worten auszudrücken: Eine gute Architektur ermöglicht einen hohen Feature-Durchsatz, ohne dass technische Verbesserungen und Bugs die Oberhand gewinnen. Die einzige Möglichkeit solche Trends zuverlässig zu erkennen, besteht darin, den Aufwand für diese Arten von Entwicklungsarbeit explizit zu erfassen. Andernfalls gehen Informationen verloren, die notwendig wären, um eine ganze Reihe bedeutender Fragen zu klären, bestimmte Erwartungen zu validieren und Schlussfolgerungen zu ziehen. Man wird nicht in der Lage sein, wesentliche Zusammenhänge zu erkennen, wie beispielsweise die folgenden:
- Nimmt der Aufwand zur Fehlerbehebung in einem bestimmten Teil des Systems kontinuierlich zu? Falls ja, ist es wahrscheinlich an der Zeit, Refactorings anzugehen, bevor es zu spät ist (=Kunde wird wütend).
- Hatten wir letztes Jahr viel Aufwand für Refactorings? Falls ja, erwarten wir dieses Jahr mehr Aufwand für Features und/oder weniger Aufwand für Bugs (=weniger Wartungsaufwand).
- Wir hatten letzten Jahr/Sprint/Release viel Aufwand für Refactorings, aber die Dinge sind nicht besser geworden (weder besserer Feature-Durchsatz noch geringerer Wartungsaufwand). Wahrscheinlich haben wir an den falschen Stellen oder auf die falsche Weise refactored. Wir brauchen also wieder Geld für Refactoring und hoffen, es dieses Mal besser zu machen (so funktionieren Feedback-Schleifen: machen, testen, lernen; machen, testen, lernen usw.).
- Plötzlich gibt es einige Bugs mit außergewöhnlichem Aufwand, aber das Team hat keine Ahnung warum. Das Bauchgefühl sagt, dass die Architektur in Ordnung ist und den Aufwand nicht rechtfertigt.Versucht der Kunde Feature-Requests als Bugs auszugeben?
- Kann ich plötzlich viel besser schlafen, weil ich mein Bauchgefühl bestätigt habe? Daten sind eine wunderbare Möglichkeit so etwas zu tun.
Inzwischen sollten noch zwei Fragen offen sein: Wie lassen sich verschiedene Arten von Entwicklungsarbeit tracken und was ist “Aufwand”? Die Antwort auf die erste ist einfach – Du hast es erraten: Issue-Typen.
Was den Aufwand betrifft, würde es den Rahmen sprengen ins Detail zu gehen. Es gibt jedoch unterschiedliche Ansätze:
- Falls in einem Projekt eine disziplinierte Zeiterfassung betrieben wird, kann die für ein Issue aufgebrachte Zeit als Aufwand betrachtet werden.
- Falls Commits mit Issues verknüpfen werden, kann die Anzahl der hinzugefügten, geänderten und gelöschten Quellcodezeilen pro Issue bei der Berechnung des Aufwand verwenden werden (erfordert Tool-Unterstützung oder die Programmierung eigener Skripte)
- Falls man einem der beiden Ansätze nicht folgen kann oder will, lässt sich die bloße Anzahl der Tickets als Aufwand betrachtet. Ein solcher Wert nicht so aussagekräftig, wie die anderen Ansätze aber es ist definitiv besser als nichts.
Ein paar Worte zu Technischen Schulden – Warum Refactorings einen eigenen Issue-Typ verdienen
Wenn Du bis hierhin gelesen hast, sollte es kein Geheimnis mehr sein, das ich ein absoluter Verfechter der Idee bin, Refactorings so explizit wie möglich zu machen. Und dass sie deshalb einen eigenen Issue-Typ verdienen. Einige Argumente habe ich bereits erwähnt. An dieser Stelle möchte ich noch einige hinzufügen und auf Gegenargumente eingehen, auf die ich im Internet und in Kundenprojekten gestoßen bin.
Es gibt zwei gefährliche und leider weit verbreitete Irrglauben, die sich gegenseitig verstärken:
- Irrglaube 1: Refactorings gehören nichts ins Backlog, weil sie keinen Geschäftswert und für Kunden keine Bedeutung haben
- Irrglaube 2: Refactorings sollten im Rahmen von funktionalen Issues (z.B. User Stories) implementiert werden
Das Komische daran ist, dass die Verfechter dieser Ansichten, die Bedeutung von technischen Schulden und Refactorings in der Regel nicht generell in Frage stellen. Im Gegenteil: sie sind der festen Überzeugung, dass technische Schulden in agilen Projekten regelmäßig abgebaut werden sollten. Leider ziehen sie aus dieser Überzeugung eine völlig falsche Schlussfolgerung. Und zwar die, dass Entwickler Refactorings als Teil einer User-Story-Implementierung, praktisch unsichtbar und nebenbei durchführen sollten. Diese Schlussfolgerung ist aus mehreren Gründen falsch:
Grund 1:
Die meisten Refactorings, die eine echte Bedeutung für das Projekt haben, können nicht mit der Hilfe der Pfadfinderregel (The Boy Scout Rule) erledigt werden:
If we all checked-in our code a little cleaner than when we checked it out, the code simply could not rot.
— Robert C. Marin. Clean Code [1].
Refactorings erfordern oftmals weitreichende Änderungen, die sich auf viele Konzepte der Architektur auswirken könnten. Solche Änderungen könnten sogar Re-Engineerings von Teilen des Systems implizieren. Das ist weder etwas, das ein Entwickler selbst entscheiden kann und sollte, noch ist es etwas, das mit einem nicht-wahrnehmbaren Aufwand nebenbei erledigt werden kann. Weitreichende Änderungen lassen sich nicht einfach in eine Reihe kleiner Boy-Scout-Regel-ähnlicher Verbesserungen zerlegen und unbemerkt, verteilt über verschiedene User-Stories, einbringen. Diese Änderungen müssen dokumentiert, entschieden, priorisiert, implementiert, reviewed und oft auch getestet werden. Das heißt: so weit wie möglich sichtbar gemacht werden.(Übrigens: Dies ist keine Kritik an der Boy-Scout-Rule).
Grund 2:
Refactorings sollten nie zu einem funktionalen Issues gehören oder nur für ein einzelnes Produkt-Feature implementiert werden. Es stimmt, dass architektonische Probleme häufig während der Implementierung eines Features zutage treten. Wir sollten solche Einsichten jedoch als Gelegenheiten betrachten zu lernen, um generelle Probleme unserer Architektur zu verstehen. Folglich sollte das Ziel eines Refactorings nicht nur darin bestehen, die Implementierung der aktuellen Funktionalität zu erleichtern, sondern auch die Implementierung von Funktionalitäten in der Zukunft. Das aktuelle Issue ist nur der Auslöser für das Refactoring, nicht aber sein inhärenter Grund. Es ist also einfach nur irreführend, ein Refactoring als Teil einer User-Story zu implementieren.
Grund 3:
Technische Schulden treten oft nicht versehentlich auf, sondern sind in den meisten Fällen das Ergebnis wohlüberlegter und bewusster Entscheidungen: “Wir müssen jetzt liefern und uns mit den Konsequenzen auseinandersetzen”. Wenn also der Ursprung der Schulden wohlüberlegt und bewusst ist, warum um alles in der Welt sollte jemand ihre Behebung hinter einer zufälligen User-Story verstecken wollen? Auf diese Weise wird die Vernünftigkeit der ursprünglichen Entscheidung, die Schulden aufzunehmen, geleugnet. Das macht einfach keinen Sinn.
Grund 4:
Wie bereits in den beiden vorhergehenden Abschnitten erwähnt: Die Vermischung von funktionalen und technischen Verbesserungen führt zu schwer verständlichem Code und entzieht dem Projekt essentielle Daten, mit denen die Softwarequalität beeinflusst werden kann.
Wie sieht es nun mit dem geschäftlichen Wert aus?
Es ist unbestreitbar, dass die Qualitätssicherung einen geschäftlichen Wert hat. Als Kunde bin ich mir immer bewusst, dass ein Teil meines Geldes für die Qualitätssicherung verwendet wird – egal in welcher Form. Refactorings sind Qualitätssicherung, und Software-Projekte ohne Refactorings sind nicht vorstellbar. Worum geht es also bei all diesen philosophischen Diskussionen?
Welchen Sinn hat es, Refactorings vor denjenigen zu verbergen, die das Budget dafür bereitstellen müssen (Product Owner, Manager)? Man sollte aufhören, Software-Projekte als “Feature Factories” zu betrachten. Man sollte die Tatsache akzeptieren, dass es in einem Software-Projekt technische Anliegen gibt, die nichts mit Funktionalität zu tun haben. Man sollten aufhören, so zu tun, als seien technische Schulden nur das Ergebnis einer schlechten Programmierung. Dass es individuelle Fehler von Entwicklern sind, es nicht beim ersten Mal richtig gemacht zu haben. Das ist nicht fair, nicht wahr und nicht redlich.
Wem nützt es, wenn technische Schulden kleingeredet werden und Refactorings im Geheimen stattfinden? Lasst uns das SNAFU-Prinzip [18] in Software-Projekten nicht zelebrieren:
Die Wirkung des SNAFU-Prinzips ist eine fortschreitende Abkopplung der Entscheidungsträger von der Realität.

SNAFU in einer Feature Factory
Inzwischen haben wir genug Wissen und auch die entsprechende Terminologie, um mit technischen Schulden, als Ingenieure und sogar als Manager auf Augenhöhe, umzugehen:
A particular benefit of the debt metaphor is that it’s very handy for communicating to non-technical people.
— Martin Fowler. Technical Debt Quadrant [5]
Wenn technische Schulden also eine Metapher sind, um Software-Entwicklung für nicht-technische Personen, wie Manager und Kunden, verständlich zu machen, warum sollten wir dann das Konzept verbergen, seinen Aufwand und seine Effektivität nicht überwachen, indem wir es explizit als Issue eines eigenen Typs behandeln? Gibt es ein überzeugendes Argument, zwischen Kunden, Managern, Product-Ownern und Ingenieuren nicht ehrlich als gleichberechtigte statt als über- und untergeordnete Stakeholder zu sprechen, indem man eine einvernehmliche Sprache verwendet?
Ich habe kürzlich an einem interessanten Talk von Dr. Gernot Starke auf der OOP-Konferenz 2020 [6] teilgenommen. Er schlägt sogar vor, einen eigenen Issue-Typ “TechDebt” zu verwenden, der zur Erfassung und Dokumentation technischer Schulden verwendet werden kann, sobald diese entstehen. Ob man solche Ansätze in einem Projekt eins-zu-eins umsetzt oder nicht, bleibt jedem selbst überlassen. Aber solche Ideen spiegeln genau die richtige Einstellung zum Umgang mit technischen Schulden wider: sie sollten explizit und für jeden sichtbar sein.
Minimaler Satz notwendiger Issue-Typen
Zu diesem Zeitpunkt sollten die notwendigen Issue-Typen nicht länger ein Geheimnis sein. Ich habe sie bereits auf die eine oder andere Weise erwähnt. Lasst mich dennoch das Gesagte systematisieren.
Issue-Typ für Features
Der Sinn eines jeden Software-Projekts besteht darin, den Endbenutzern mit Features zu versorgen. Selbst wenn Du ein Framework entwickelst, das von anderen Entwicklern verwendet werden soll. Ein neues API in Deinem Framework ist ein Feature für seine Endbenutzer.
Daher benötigt jedes Projekt mindestens einen Issue-Typ für Features. In einem Scrum-basierten Projekt ist der üblicherweise verwendete Issue-Typ User Story. Falls man Scrum nicht verwendet und/oder nicht an spezielle Namenskonventionen gebunden ist, würde ich den naheliegendsten Namen für diesen Issue-Typ verwenden, nämlich Feature.
Bitte fühle Dich nicht gezwungen, mehr als einen Issue-Typ für funktionale Änderungen zu verwenden, es sei denn, Du siehst darin einen klaren Mehrwert und einen Beitrag zur Lösung konkrete Probleme. Fange im Zweifelsfall mit einem Issue-Typ an und fügen später weitere hinzu. Zögere nicht, von einem Issue Tracker vorgegebene Standard-Issue-Typen zu entfernen, falls Du keine klaren Regeln definieren kannst, wann diese zu verwenden sind. Und sei bitte konsequent: entferne die Typen sofort, behalte sie nicht für später, nur für den Fall, dass Du irgendwann den Sinn verstehen. Höchstwahrscheinlich wird das nicht passieren. Aber solange sie existieren, werden sie Dich und andere verwirren und kognitiven Aufwand verschwenden. Befreien Dich so schnell wie möglich von dieser Last.
Ich möchte es noch einmal ausdrücklich festhalten:
- Nein, Du brauchst keine Epics, falls Du keinen Sinn darin siehst, Features zu gruppieren. Es gibt keine superschlauen Gründe hinter Epics. Du wirsts nichts verpassen, wenn Du keine Epics verwendest.
- Nein, Du brauchst keine Improvements oder Enhancements, um Erweiterungen bestehender Features auszudrücken. Eine Erweiterung eines bestehenden Features ist auch ein (kleineres) Feature. Es ist also nicht verkehrt, ein Issue vom Typ Feature dafür zu erstellen.
- Und bitte verwende Feature und User Story nicht gleichzeitig, es sei denn, Du kannst kristallklare Regeln dafür angeben, wann was zu verwenden ist (ich kenne keine derartigen Regeln).
Was ist mit Operationalen Anforderungen?
Brauchen wir einen eigenen Issue-Typ, um Änderungen zu erfassen, die sich auf Themen wie die Verbesserung der Performance oder des Speicherverbrauchs, die Handhabung von Portabilitäts- und Sicherheitsbelangen, die Unterstützung neuer Plattformen, Protokolle usw. beziehen? Nicht unbedingt, es sei denn, wir müssen aus irgendwelchen Gründen den Aufwand für dieser Art von Arbeiten explizit erfassen.
Vom Wesen her sind operationale Anforderungen auch Features eines Produkts. Auch wenn das klassische Requirements Engineering [7] sie als nicht-funktional betrachtet. Das bedeutet aber nicht, dass damit die Existenz von funktionale und nicht-funktionale Features ausgeschlossen wäre. Sie sind Features, weil sie einen wahrnehmbaren Impact auf die Software haben. Wenn eine Operation schneller als bisher ausgeführt werden kann, wird der Kunde das merken. Wenn eine Applikation auf eine neue Plattform portiert wird, handelt es sich um ein außerordentlich großes Feature, weil es den gesamten Funktionsumfang der Applikation für eine Menge neuer Benutzer verfügbar macht. Die Umsetzung operationaler Anforderungen ist weder Verschwendung noch Wartungsaufwand oder nur technische Arbeit. Operationale Anforderungen werten die Software auf und sind daher Features.
Issue-Typ für Programmfehler
Das ist einfach. Man braucht einen separaten Issue-Type, um Fehler und unerwartetes Verhalten zu erfassen. Und der beste Name dafür ist Bug. Die Anzahl der Bugs ist eine wichtige Qualitätsmetrik eines Systems; die Behebung von Bugs ist eine wichtige Qualitätssicherungsmaßnahme. Man sollte die Bugs also besser im Auge behalten. Reine Bug-Tracker (wie z.B. Bugzilla) sind die Vorläufer der heutigen, voll ausgestatteten Issue-Tracker. Bugs waren schon immer essentiell, und daran hat sich bis heute nichts geändert.
Dazu gibt es also nicht viel zu sagen. Dennoch gibt es in diesem Zusammenhang einen entscheidenden Ratschlag: sei ehrlich zu Dir selbst und fixe Bugs nicht nebenher.
Wenn wir an einem Feature oder einem Refactoring arbeiten, kann es passieren, dass wir zufällig auf einen Fehler stoßen, der vorher niemandem aufgefallen ist. Zum Beispiel, weil er uns schon beim bloßen Betrachten des Codes auffällt. Oder wenn ein Test, der für eine neue Funktionalität hinzugefügt wurde, fehlschlägt und wir durch Nachverfolgung des Grundes auf den Fehler stoßen. Vor allem, wenn der Fix sehr klein wäre, vielleicht sogar nur ein Einzeiler, ist die Versuchung groß, kein großes Aufhebens um den Fehler zu machen und ihn einfach als Teil des aktuellen Issues zu beheben. Auch wenn es auf den ersten Blick Zeit spart, ist es dennoch keine gute Idee. Wie wir wissen, ist es eine schlechte Praktik, nicht zusammenhängende Änderungen unter einem Issue zu mischen. Indem wir den Bug undokumentiert verschwinden lassen, entziehen wir dem Projekt zudem wertvolle Informationen (Rückverfolgbarkeit und Monitoring).
Bitte sei diszipliniert und erstellen für jeden entdeckten Fehler, ein Bug-Issue. Der Zeit-Overhead ist minimal, aber Deine Kollegen und Dein zukünftiges Ich werden es Dir danken. Übrigens: ein Bugfix ist fast nie ein Einzeiler – denn jeder Bug sollte durch einen Test abgedeckt werden.
Issues für Refactorings und Re-Engineerings
Wir brauchen einen eigenen Issue-Typ, um architektonische Verbesserungen zu erfassen, Arbeiten im Zusammenhang mit der Reduzierung der technischen Schulden zu handhaben, Re-Engineerings durchzuführen und Ähnliches. Der Einfachheit halber kann man diesen Issue-Typ Refactoring nennen. Andere Bezeichnungen wie Architectural Improvement sind auch in Ordnung. Aufgrund der im ersten Teil beschriebenen inhärenten Probleme, würde ich jedoch von der Verwendung von Technical Story oder Architecture Story abraten.
Das charakteristische Merkmal dieser Arten von Entwicklungsarbeit ist ihr Zweck, Code-Verbesserungen vorzunehmen, die darauf abzielen, den kognitiven Aufwand für die Implementierung neuer Funktionalität zu verringern und die Wahrscheinlichkeit von Bugs und Fehleinschätzungen im Code zu reduzieren. Hier sind einige Beispiele:
- Verbesserung der Code-Verständlichkeit/Lesbarkeit
- Vereinfachungen des Codes
- Verbesserungen, um den Code selbsterklärend zu machen (einschließlich der Umbenennung von Bezeichnern und Modulen)
- Umgestaltung/Neuandordnung von Code-Teilen zur Erhöhung des Kohäsion oder zur Einhaltung des Single-Responsibility-Prinzips
- Hinzufügen oder Verbessern von Dokumentation
- Verbesserung der Wiederverwendbarkeit, z.B. die Auslagerung häufig verwendeter Logik in separate Klassen/Funktionen/Module
- übergreifende technische Änderungen, die auf eine Verbesserung der Architektur abzielen, z.B. Umstellung auf ein neues Framework, welches die Umsetzung anstehender Anforderungen erleichtert
- Entfernen von totem Code
- umfangreiche kosmetische Änderungen (Formatierung, Stil)
- umfangreiche Fixes von Findings von statischen Code-Analyzern/Checkern
- und andere architektonische Änderungen jeder Größe
Übrigens ist der Implementierungsaufwand kein Unterscheidungsmerkmal für ein Refactoring. Refactorings können groß oder klein sein. Wenn man an eine Feature arbeitet und feststellt, dass eine Berechnung bereits an zwei verschiedenen Stellen verwendet wird und das aktuelle Feature sie ein drittes Mal benötigt, wäre es eine kluge Entscheidung, diese Berechnung in eine separate Funktion auszulagern, um Code-Duplikation zu vermeiden. Selbst wenn diese Berechnung minimal ist, wie zum Beispiel die Berechnung des Volumens einer Kugel, handelt es sich immer noch um ein Refactoring. Und der beste Ansatz wäre, die aktuelle Arbeit für einen Moment zu unterbrechen und ein Refactoring-Issue zu erstellen, in welchem das Was und Warum kurz beschrieben wird. Danach das Issue durch Hinzufügen der neuen Funktion und Anpassung der beiden bestehenden Verwendungsstellen zu implementieren. Anschließen kann man mit der Implementierung des Features fortfahren, welches nun die neue-hinzugefügte Funktion nutzen kann. Eine mögliche Alternative könnte darin bestehen, die neue Funktion als Teil der Feature-Implementierung hinzuzufügen und ein Refactoring-Issue zu erstellen, um die beiden übrigen Verwendungsstellen später anzupassen. Unter keinen Umständen sollten man jedoch diese voneinander unabhängigen Anpassungen im Rahmen des aktuellen Features vornehmen.
Issue-Typ für Wartung
Neben Refactorings gibt es in Software-Projekten noch andere Arten von technischer Arbeit, die einen eigenen Issue-Typ verdienen. Und lasst mich die Katze gleich aus dem Sack lassen: Ich schlage vor, für sie den Namen Task zu verwenden. Einfach ausgedrückt, handelt es sich um alle anderen Arten von Entwicklungsanforderungen (Developmental Requirements [4]), die keine Refactorings sind. Diese Definition ist jedoch nicht sehr hilfreich, also versuche ich präziser zu sein. Ich denke, es gibt einige Kategorien von Tasks:
Software-Entwicklungsprozess & Tooling
- Konfigurieren von CI/CD-Pipelines (z.B. Modifizieren von Jenkinsfile)
- Anpassen von Konfigurations- und Projektdateien von IDEs, Build-Tools, Code-Checkern usw.
- Implementieren von Hilfs-Skripten für die Entwicklungsarbeit
Infrastruktur
Zu dieser Kategorie gehören Arbeiten wie das Upgraden auf neue Bibliotheks-/Framework-/Sprach-Versionen oder die Umstellung auf andere Technologien. Vielleicht ist Dir bereits im letzten Abschnitt aufgefallen, dass ein Wechsel zu einer anderen Technologie auch ein Refactoring sein kann. Ob es sich um eine Task oder ein Refactoring handelt, hängt vom Grund bzw. Ziel ab. Es ist ein Refactoring, falls das Ziel darin besteht, neue Arten von Funktionalitäten der neuen Technologie zu nutzen, die bei der Implementierung neuer Features helfen können. In anderen Fällen handelt es sich nur um eine Task. Beispiele:
- das aktuelle Framework ist buggy und wird nicht gut gepflegt, so dass man keine andere Wahl hat, als zu wechseln
- eine neue Version einer Bibliothek funktioniert nicht mit einer alten, so dass ein Upgrade unerlässlich ist
- eine Sicherheitslücke in einer Bibliothek, auf die man angewiesen ist, wurde behoben und man braucht die neue Version (je nach konkretem Fall kann ein Bug auch ein gültiger Issue-Typ sein)
- regelmäßige Aktualisierungen auf neue Versionen (z.B. um in der Zukunft erheblichen Integrationsaufwand zu vermeiden) ist Teil des Entwicklungsprozesses
Vermeidbare Verschwendung
Dies ist die komplizierteste Kategorie von Task, da die Unterscheidung zu Refactorings fließend sein kann. Es ist schwer, eine felsenfeste Definition zu geben. Lasst uns jedoch mit einigen Beispielen beginnen.
Stell Dir vor, Du hätten beschlossen in Deinem Projekt Richtlinien für den Code-Style festzulegen (oder zu ändern) und den vorhandenen Code neu zu formatieren. Entweder auf einmal oder Schritt für Schritt. Es ist in Ordnung, es als Refactoring auszudrücken, denn höchstwahrscheinlich gibt es gute Gründe für diese Entscheidung, die darauf abzielen, die Lesbarkeit des Codes zu verbessern. Nach dem Refactoring erwartest Du von allen Entwicklern, dass sie sich an die neuen Richtlinien halten und nur Code produzieren, dem mit dem neue Style konform ist. Alle zukünftigen Style-Verletzungen, die Korrekturen erfordern, sind also keine Refactorings mehr – sie sollten unter Task behandelt werden. Es handelt sich um vermeidbare Verschwendung, die entweder durch mangelnde Disziplin, schlechte Kommunikation, schlechte Werkzeuge oder Nachlässigkeit entsteht. Man sollte diese Art von Aufwand in einem Projekt auf ein Minimum reduzieren. Dasselbe gilt für die Korrektur von Tippfehlern.
Eine weitere Kategorie von vermeidbarer Verschwendung sind Korrekturen im Zusammenhang mit instabilen oder anderweitig problematischen Tests. Normalerweise sollten angemessene Tests zusammen mit der Implementierung des Haupt-Issues (Feature, Buger, sogar einige Refactorings können Tests erfordern) committed werden. Falls diese Tests anfangen Probleme zu verursachen (z.B. weil sie zufällig fehlschlagen), kann der zusätzliche Aufwand als Verschwendung angesehen werden.
Im Allgemeinen können auch Änderungen im Zusammenhang mit schlechten Programmierpraktiken (z.B. die Verwendung von obsoleten Funktionen mit Sicherheitslücken), die Korrekturen erfordern, als vermeidbare Verschwendung angesehen werden.
Alles andere
Ich entschuldige mich für diese Kategorie. Es gibt jedoch einige schwer klassifizierbare Fälle wie das Hinzufügen/Ändern von Copyright-Kommentaren, die ebenfalls unter Tasks behandelt werden sollten.
Randfälle und warum einen Unterschied zwischen Refactorings und Wartung machen
Leider gibt es auch einige weniger offensichtliche Fälle. Zum Beispiel das Verbessern/Hinzufügen von Dokumentation oder das Hinzufügen neuer oder die Verbesserung bestehender Tests.
Manchmal stößt man beim Versuch Code zu verstehen auf ein Konstrukt ohne oder mit schlechter Dokumentation, so dass man einige Zeit damit verbringt, es zu verstehen. Am Ende fühlt man sich geneigt, seine Erkenntnisse durch das Hinzufügen von Dokumentation auszudrücken. Was ist in so einem Fall zu tun? Angesichts der Tatsache, dass Dokumentation die Verständlichkeit von Code verbessert und damit möglicherweise den kognitiven Aufwand zum Verständnis von Code verringert, können Verbesserungen der Dokumentation als Refactoring-ähnliche Änderungen betrachtet werden. Andererseits könnte man argumentieren, dass das Hinzufügen einer ordnungsgemäßen Dokumentation von Anfang an hätte erfolgen müssen, so dass die Verbesserung der Dokumentation eher ein Wartungsaufwand ist.
Um die richtige Entscheidung zu treffen, hilft es sich daran zu erinnern, warum eine Unterscheidung zwischen Refactoring und Wartung überhaupt notwendig ist. Das Schlüsselwort ist: Monitoring (siehe Abschnitt “Issue Tracker als Grundlage für Qualitäts-Monitoring”). Wir sind daran interessiert, den Refactoring-Aufwand separat zu erfassen, um die Wirksamkeit unserer Refactorings zu bewerten. Nach einem gewissen Refactoring-Aufwand erwarten wir, dass der Feature-Durchsatz steigt und/oder der Bug-Aufwand sinkt. Dies ist etwas, das wir nicht unbedingt von Wartungsarbeiten erwarten. Dennoch sind wir daran interessiert den Wartungsaufwand separat zu erfassen, da es stets zu den Projektzielen gehören sollte, solchen Aufwand so weit wie möglich zu reduzieren. Wenn wir zu viel Zeit damit verbringen unsere Werkzeuge zu konfigurieren, Versionskonflikte zwischen Bibliotheken zu beheben oder den Code-Style zu verbessern, anstatt Features zu implementieren, stimmt in unserem Projekt etwas nicht, und wir sollten etwas unternehmen.
Handhabung von Mikro-Verbesserungen – Zurück zur Boy-Scout-Rule
Es ist nicht möglich, für jedes kleine Problem (wie z.B. die Behebung eines Tippfehlers, einer falschen Einrückung oder das Entfernen eines unbenutzten Imports), das beim Programmieren auftritt, ein eigenes Ticket zu erstellen. Wir wollen jedoch nicht gegen die allgemeine Regel verstoßen, dass nicht-zusammenhängende Änderungen nicht vermischt werden sollten. Wie können wir dieser Herausforderung begegnen?
Wir bei Cape of Good Code verwenden ein Konzept, das wir “Never-Ending Issues” nennen. Es handelt sich dabei um reguläre Issues in unserem Tracker, die jedoch nicht dazu bestimmt sind, jemals geschlossen zu werden. Sie werden verwendet, um kleine Refactoring-ähnliche und Wartungs-Änderungen vorzunehmen. Der einfachste Ansatz besteht also darin, mit zwei Never-Ending-Issues zu beginnen: einem Refactoring und einem Task.
Never-ending Refactorings können verwendet werden, um Dinge wie die Umbenennung von Bezeichnern zu committen, um sie aussagekräftiger zu machen; für kleine Verbesserungen der Dokumentation oder um gelegentlich Dead-Code zu entfernen.
Never-ending Tasks können für kleine kosmetische Änderungen und andere Arten von kleinen Wartungaufgaben verwendet werden.
Wenn Dir das “never-ending”-Konzept nicht gefällt, kannst Du solche Issues für kleine, gelegentliche Änderungen pro Sprint/Release/Monat/Jahr erstellen und sie anschließend schließen.
Der Scope solcher Never-Ending-Issues sollte jedoch nur für kleine Änderungen reserviert werden, die keine eigene Issues verdienen. Man sollte darauf achten, dass Never-Ending-Issues im Projekt nicht missbraucht werden. Sie sind ein ausgezeichneter Kompromiss, sollten aber nicht dazu benutzt werden, Regeln über Bord zu werfen.
Eltern-Kind-Beziehungen und Dekomposition
Bislang haben wir vier Arten von Issues: Feature/User-Story, Bug, Refactoring und Task. Sind sie ausreichend, um das Konzept der Task-Dekomposition, d.h. die Zerlegung größerer Issues in kleinere Teilaufgaben, umzusetzen? Nun, ja und nein.
Um ehrlich zu sein, gefällt mir Jiras Idee der Sub-Tasks. Einen separaten Issue-Type für die Dekomposition zu haben, vermeidet Verwirrung und macht deutlich, dass das entsprechende Issues nur für die Unterteilung bestimmt ist. Insbesondere haben Sub-Task vom Wesen her keinen eigenen Issue-Type – sie “erben” ihren Typ von ihren Eltern. Bitte nicht falsch verstehen: “Typ-Vererbung” ist kein Konzept, das in Jira technisch implementiert ist. Es sollte vielmehr unsere mentale Sichtweise auf Sub-Tasks sein. D.h. der Aufwand für eine Sub-Tasks eines Bugs sollte als Bug-Aufwand gezählt werden, der Aufwand für eine Sub-Task eines Features ist Feature-Aufwand usw. Es ist nicht besonders sinnvoll, die Anzahl der Sub-Tasks oder den Aufwand für Sub-Tasks als separate Metrik zu erfassen.
Wäre es dennoch möglich ohne Sub-Tasks auszukommen? Theoretisch ja. Indem wir stattdessen Tasks verwenden. Auf diese Weise würden Tasks zwei verschiedene Zwecke erfüllen. Wenn eine Task als Kind eines anderen Issues erscheint, hat sie alle Eigenschaften einer Sub-Tasks, insbesondere keinen eigenen Issues-Typ. Wenn die Task als eigenständiges Issue verwendet wird, sollte sie als Wartungsaufwand behandelt werden.In diesem Szenario könnte es passieren, dass Tasks andere Tasks als Kinder haben. Man sieht also, dass ein solcher Ansatz ein großes Verwirrungs-Potential in sich birgt. Im Übrigen wird so etwas nicht standardmäßig von Jira unterstützt, denn Tasks können nicht als Kinder von anderen Issues außer Epics angelegt werden. Daher befürworte ich eindeutig die Lösung mit Sub-Tasks.
Abbildung einer gemeinsamen technischen Infrastruktur für verschiedene Features
Manchmal weiß man schon im Voraus, dass mehrere Features implementieren werden sollen, welche sich eine gemeinsame Infrastruktur teilen. Beispielsweise gemeinsame Datenbanktabellen oder ein neues Kommunikationsprotokoll. Man erstellt also ein separates Issue, um diese technischen Aspekte zu implementieren. Entweder um explizit auszudrücken, dass die Infrastruktur von beiden Features genutzt wird und/oder um die Lösung zu strukturieren und/oder weil die entsprechende Implementierungsarbeit von einer bestimmten Person übernommen wird. Und obwohl es allesamt legitime Gründe für eine Dekomposition sind, können wir ziemlich schnell in eine problematische Situation geraten. Das folgende Beispiel zeigt zwei gebräuchliche Ausdrucksformen für eine solche Aufteilung: mit und ohne Epics.
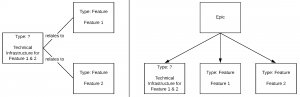
Falscher Ansatz technische Arbeit abzubilden, die sich auf mehrere Features bezieht
Das Problem ergibt sich aus der Tatsache, dass technische Infrastruktur, die der Codebasis zur Implementierung bestimmter Features hinzugefügt wird, als Feature-Aufwand und nicht als etwas anderes gezählt werden sollte. Es ist jedoch nicht ohne weiteres möglich, dies mit unserem derzeitigen Satz von Issue-Typen und der obigen Dekomposition auszudrücken. Wenn wir eine Sub-Task für das Infrastruktur-Issue verwenden, haben wir keine Möglichkeit, ihren logischen Typ abzuleiten, da sie mit keinem Feature verbunden ist. Folglich bräuchten wir einen zusätzlichen Issue-Typ, wie zum Beispiel “Feature-Sub-Task”, um das obige Szenario zu modellieren.
Glücklicherweise gibt es eine bessere Lösungen, die unser Issue-Typen-Modell nicht unnötig verkomplizieren.
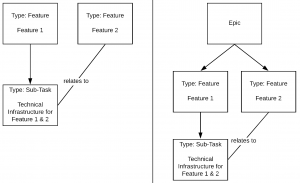
Richtige Ausdrucksmöglichkeiten für technische Infrastrukturarbeiten, die sich auf
mehrere Issues beziehen.
Wir können das Issue für der technischen Infrastruktur einfach zu einer Sub-Task eines der beiden Features machen. Wahlweise können wir eine separate Beziehung verwenden, um auszudrücken, dass das andere Feature ebenfalls die Infrastruktur nutzt.
Auf den ersten Blick mag dies wie eine willkürliche Lösung erscheinen, weil der Aufwand für die technische Infrastruktur nur einem der beiden Features zugeschrieben wird, obwohl es logischerweise zu beiden gehört. Dies ist jedoch ein Trugschluss. Es ist bei jedem Projekt ganz normal, dass eine beliebige Anzahl von Features, die in der Vergangenheit für ein Feature hinzugefügte technische Infrastruktur wiederverwendet. Es wird von niemanden erwartet, das allererste Issue identifizieren müssen, unter dem die entsprechende Infrastruktur zur Codebasis hinzugefügt wurde, nur um eine entsprechende Beziehung herzustellen. Der obige Fall stellt eher eine Ausnahme dar, da uns zufällig zwei Features gleichzeitig bekannt sind, die sich auf dieselbe Infrastruktur stützen. Diese Tatsache durch Beziehungen explizit zu modellieren, ist zwar ein Nicht-to-have, aber sicherlich nichts, dem wir zu viel Aufmerksamkeit widmen sollten. Bei einer Task-Dekomposition sollte man jedoch daran denken, das der Typ des Aufwandes für ein Kind-Issues stets vom Typ des Eltern-Issues ableitbar sein muss.
Organisatorische und andere Issues
Wenn man den Issue-Tracker verwendet, um alle Arten von Arbeiten in einem Software-Entwicklungsprojekt zu verfolgen, dann wird man höchstwahrscheinlich Aufgaben haben, die nicht zu Code-Änderungen führen. Es könnten organisatorische Aufgaben sein, wie z.B. die Einarbeitung neuer Mitarbeiter oder andere Arten von Arbeit, wie z.B. die Durchführung von Technologie-Evaluierungen. Welche Arten von Issues sollten man für diese Arbeit verwenden? Nun, wenn man diese Aufgaben im selben Issue-Tracker-Projekt wie die Entwicklungsarbeit erfassen möchten, kann man tatsächlich beliebige Typen wählen. Sie sind für die hier beschriebenen Überlegungen nicht relevant; sie sind nicht Teil des beschriebenen Modells. Das Modell berücksichtigt nur Issues, die mit Code-Änderungen verbunden sein können.
Man könnte für diese Art von Arbeit sogar Tasks verwenden. Mit der folgenden mentalen Regel: Tasks mit Code-Änderungen sind Wartungsarbeiten, Tasks ohne sind alles andere.
Zusammenfassung und Takeaways
Das praktischste Takeaway ist, dass jedes Softwareentwicklungsprojekt mindestens vier Haupt-Issue-Typen benötigt:
- Feature oder User Story – für Produkt-Features (funktionale oder nicht-funktionale)
- Bug – für Fehler und unerwartetes Verhalten
- Refactoring – für architektonische Verbesserungen und dergleichen
- Task – für Wartungsarbeiten
- und optional Sub-Task – zur Dekomposition für aller anderen Issue-Type
Es mag überraschen, dass wir letztlich auf zwei Typen für technische und nur einen für funktionale Arbeit kommen. Bei vielen Projekten ist es eher das Gegenteil: es gibt mehrere Typen für funktionale Arbeit und nur einen oder keine Typen für technische Arbeit. Tatsächlich ist es wenig überraschend, denn funktionale Anforderungen sind einfach, akzeptiert und gut verstanden, ihre Handhabung erfordert keine tiefen Einblicke:
Functional requirements are typically binary in nature: you either meet a requirement or you don’t. There are no shades of grey, no extra-Boolean possibilities lurking between true and false. It either passed or it failed. That’s the nice thing about functional requirements. They are precise. There is no approximation.
— Kevlin Henney. Inside Requirements [4].
In diesem Beitrag habe ich mich an die weniger klaren und präzisen Dinge gewagt und versucht, technischen Issues in Softwareprojekten auf eine strukturierte Art und Weise zu begegnen. Insbesondere habe ich versucht zu begründen, warum technische Schulden eine maximale Sichtbarkeit verdienen.
Als ich für diesen Post recherchierte, stieß ich auf ein interessantes Paper: Requirements Communication in Issue Tracking Systems in Four Open-Source Projects [2]. Durch die Analyse der natürlichsprachlichen Kommunikation in Issue-Tracking-Systemen versuchten die Autoren, Issue-Typen zu kategorisieren, die dort tatsächlich repräsentiert sind: Dies sind die Ergebnisse:
The following issue types were discovered: 1) Feature-Related – information, related to a new software feature or software requirements, 2) Bug-Related – software failures and problems, 3) Refactoring-Related – software changes that neither affect the functionalities nor the qualities of the software (besides maintainability), 4) SE Process-Related – discussions about the general SE process, e.g. if a developer notices that tests should be run more frequently in the project or if documentation should be relocated,..
Die vier vorgeschlagenen Problemtypen sind praktisch deckungsgleich mit denen, die auch in der natürlichen Kommunikation vorkommen. Ich denke, die Ergebnisse sind recht beeindruckend: sie zeigen, dass diese vier Issue-Typen wesentliche Anliegen und Arten der Entwicklungsarbeit darstellen. Dies ist eine weitere Bestätigung dafür, dass die vorgeschlagene Differenzierung grundlegend ist.
Aber genug geredet, lasst mich mit einer Liste klarer Regeln schließen.
11 Regeln, um im Dschungel der Issue-Typen zu überleben
- Verwende keine Issue-Typen, deren Bedeutung Du nicht vollständig verstehen
- Behalte keine Standard-Issue-Typen in Deinem Issue-Tracker, die Du nicht verwenden. Entferne sie unverzüglich.
- So wenige wie möglich, so viele wie nötig – dies gilt uneingeschränkt für Issue-Typen (4 Haupt-Issue-Typen)
- Verstecke technischen Schulden vor niemandem. Mache sie so sichtbar wie möglich durch einen separaten Issue-Typ.
- Verwende keine “Technical Stories”. Sie sind einfach zu ambivalent.
- Verwende nicht “Als <Rolle>, möchte ich <Ziel> um <Nutzen>”-Vorlage, um technische Anliegen auszudrücken.
- Betrachte Sub-Tasks von Features oder User Stories nicht als technische Issues. Die Zerlegung eines funktionalen Problems führt nur zu kleineren Teilen, deren Zweck immer noch funktional ist.
- Vermische nicht Änderungen von nicht-verwandten Issue-Typen (wie z.B. schnelle Refactorings als Teil von Features usw.).
- Fixe Bugs nicht nebenher.
- Nutze Never-Ending-Issues, um kleinen Verbesserungen zu handhaben
- Vergewissere Dich, dass alle Projektbeteiligten das gleiche Verständnis von Issue-Typen teilen. Dokumentiere den Zweck jedes Issue-Types explizit in projektweiten Guidelines.
Was hältst Du von dem Ansatz? Siehst Du Randfälle, die nicht in dieses Modell passen? Lass es mich wissen. Ich freue mich darauf, sie zu diskutieren. Zögere nicht, Kommentare zu hinterlassen.
Referenzen
- Robert C. Martin (2008). Clean Code. A Handbook of Agile Softeare Craftmanship. PRENTICE HALL
https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882
- Thorsten Merten et al. (2015). Requirements Communication in Issue Tracking Systems in Four Open-Source Projects,
http://ceur-ws.org/Vol-1342/02-reprico.pdf
- Kevlin Henney. Architecture with Agility.
http://sddconf.com/brands/sdd/library/Architecture_with_Agility.pdf
- Kevlin Henney (2003). Inside Requirements.
https://de.slideshare.net/Kevlin/inside-requirements
- Martin Fowler (2009). TechnicalDebtQuadrant.
https://martinfowler.com/bliki/TechnicalDebtQuadrant.htm
- Dr. Gernot Starke (2020). 1×1 technischer Schulden.
https://www.oop-konferenz.de/oop2020/programm/konferenzprogramm/sessiondetails/action/detail/session/nmi-2/title/1×1-technischer-schulden.html
- IEEE standard 729. Classification of Software Requirements.
https://www.geeksforgeeks.org/software-engineering-classification-of-software-requirements
- Ajay Badri. User Stories and Technical Stories in Agile Development.
https://seilevel.com/requirements/user-stories-technical-stories-agile-development-productmanagement
- Robert Galen (2013). Technical User Stories – What, When, and How?
https://rgalen.com/agile-training-news/2013/11/10/technical-user-stories-what-when-and-how
- Rachel Wright (2019). Different Jira Issue Types.
https://www.jirastrategy.com/questions/different-jira-issue-types
- KathrynEE et al. (2018). Agile process work item types and workflow.
https://docs.microsoft.com/en-us/azure/devops/boards/work-items/guidance/agile-process-workflow
- Valerie Andrianova (2018). How We Handle External Requests in YouTrack
https://youtrack-support.jetbrains.com/hc/en-us/articles/115001019644-How-We-Handle-External-Requests-in-YouTrack
- Chris Taylor et al. (2014). Feature vs Task vs Story.
https://community.atlassian.com/t5/Jira-Software-questions/Feature-vs-Task-vs-Story/qaq-p/418930
- nivlam et al. (2013). Relationship between user story, feature, and epic?
https://softwareengineering.stackexchange.com/questions/182158/relationship-between-user-story-feature-and-epic
- Thom Holwerda (2008). WTFs/m.
https://www.osnews.com/story/19266/wtfsm/
- Chris Beams (2014). How to Write a Git Commit Message.
https://chris.beams.io/posts/git-commit/
- Sean Patterson (2013). Developers Tip: Keep Your Commits “Atomic”.
https://www.freshconsulting.com/atomic-commits/
- SNAFU principle.
https://www.techfak.uni-bielefeld.de/~joern/jargon/SNAFUprinciple.HTML
- Ken Schwaber, Jeff Sutherland (2013). The Scrum Guide. The Definitive Guide to Scrum: The Rules of the Game.
https://www.scrumguides.org/docs/scrumguide/v1/Scrum-Guide-US.pdf
- https://en.wikipedia.org/wiki/Scrum_(software_development)
- https://en.wikipedia.org/wiki/SNAFU
{kind=link}