{kind=link}
Technical Debt
The Most ‘Striking’ Way To Explain Technical Debt – Even to Your Kids & Managers
White Stripes on the Tail Put Maschine Guns of a Fighter Plane Out of Action - A Technical Debt Story
Practical guide on how to improve software quality and establish effective monitoring through the right selection of issue types.
Do you exactly know which issues types to use for your issue tracker and when to use which? Does everyone in your project know about your approach? Are issue types always used consistently in your project? Should you use Technical User Stories or not? Do you use issue types at all? Do you find it reasonable that different issue trackers have such different default issue types? Have you ever thought about issue types at all?
If your answer to one or more of the questions above is “no”, or “don’t know” or “I don’t care”, you are not alone, and this post might be of interest to you. It reveals the chaos behind the often mindless, uncertain and inconsistent usage of issue types in many software projects. It shows why a conscious and purposeful application of issue types can lead to better code comprehensibility as well as better quality monitoring and decision making in projects. It suggests a minimal set of reasonable issue types along with understandable rules for their usage. In particular, it reasons why a separate issue type is needed to deal with technical debt.
If you just believe in summaries or are short of time, but are eager to follow the recommendations here and want to see what happens, just feel free to switch to the section Minimal Set of Needed Issue Types and configure your issue tracker accordingly. However, if you are ready for the whole story, you’re welcome to start the journey right here.
Remark: I am aware of the difference between “refactoring” and “re-engineering”. However, for the sake of simplicity, I will use the term “refactoring” as a generic term for both.
In our consulting projects on software quality we often discover a similar situation: neither developers nor architects or responsible project managers have a clear picture of how much effort is spent on feature implementations, bug-fixing or refactorings in the project. As a consequence, it becomes almost impossible for them to reliably measure the effects of improvement activities and efficiently handle technical debt. There is often great uncertainty regarding the sense and benefits of refactorings executed in the past. When we ask, whether such improvements increased the feature throughput or reduced the number of bugs or any maintenance effort, the answers are often very vague. The information is mainly based just on gut feelings and memories of people who happened to be involved in the corresponding activities.
In some cases, project stakeholders are not even sure which entities in their issue trackers (or project management tools) represent product features. In other cases, developers are not sure about what to consider as a bug: just errors popping up at customers or also internal problems discovered by themselves or their peers. However, the truth is that in almost all projects, architectural improvements are not captured at all. In the best cases, they are discussed in meetings involving decision-makers and sparsely documented in wikis or other unstructured documents. More often such issues exist just in the heads of developers. The corresponding work is not captured in issue trackers and often is not explicitly visible in commits as if it’s something that is not part of the development process.
This lack of structured information about significant development activities makes it hard to make the right decisions about how to spend the project budget. And it ultimately degrades the overall software quality.
According to our observations, one of the reasons for this situation is the uncertainty regarding the correct and consistent usage of issue trackers and issue types. There are just no universally understandable and pragmatic rules.
This contribution is an attempt to identify and document such rules.
If you look at the standard issue types of popular issue trackers (sketched in the table below), you will notice that there is a considerable variety of types for functional issues. These are issues representing changes related to product features, aka business functionality. Jira has even four of such feature-related types of different granularity (Epic, New Feature, User Story and Improvement). There is also some variation of types representing work related to errors. Usually, this type is just called “Bug”. YouTrack is a real exception by suggesting (seriously?!) three different issue types for errors: Bug, Cosmetic and Exception.
| Jira | YouTrack | Azure Boards | Trac | Redmine | ||
|---|---|---|---|---|---|---|
| functional | Epic | ✘ | ✘ | |||
| (New) Feature | ✘ | ✘ | ✘ | ✘ | ||
| User Story | ✘ | ✘ | ||||
| Improvement | ✘ | |||||
| Enhancement | ✘ | |||||
| errors | Bug | ✘ | ✘ | ✘ | ✘ | |
| Defect | ✘ | |||||
| Cosmetic | ✘ | |||||
| Exception | ✘ | |||||
| misc | Task | ✘ | ✘ | ✘ | ✘ | |
| Sub-Task | ✘ | |||||
What all popular issue trackers have in common, however, is that all of them lack issue types for technical/architectural work. As if it were something that doesn’t deserve visibility. Admittedly, Azure Boards with its “Architectural” “Value Area” field for User Stories is a well-meant (and not more!) exception – but more about that later (please refer to the section on Technical (User) Stories).
You will now say: Stop! No types for technical work? But that’s exactly what Tasks are for, aren’t they? Well, let’s see.
This is how a Task is defined by Atlassian in Jira:
A task represents work that needs to be done
— Rachel Wright. Different Jira Issue Types [10]
If you believe anything more meaningless is not possible (except for issue types representing work that doesn’t need to be done), I can go one further: This is the default description of a Task in the Jira Cloud UI:
A task that needs do be done
— Jira UI Task description
So basically Jira says “a Task is a task”. This is also known as a tautology – a redundant statement [22]. So the market leader for issue trackers does not tell us what tasks are actually for. Perhaps we can find a more useful definition somewhere else:
Tasks can include development, testing, and other kinds of work
— Agile process work item types and workflow [11]
Well, thanks a lot. It’s very reassuring to know that a Task in a software development project may also contain development work. As if the other issue types are not for development. So Microsoft doesn’t have a clear definition for a task either – it’s again a swiss army knife.
Could it be that tool suppliers are not the right contact to look for such kind of definitions? After all, corresponding tools should be usable with any kind of development process, so that tool suppliers deliberately remain vague and leave it to the respective project to make sense of the issue types?
Let’s see what Scrum has to say about Tasks:
The product backlog items may be broken down into tasks by the development team
— Wikipedia. Scrum [20]
Interesting – Scrum doesn’t say anything about the type of work represented by a task. It regards tasks merely as a means for decomposing and organizing work around functional issues.
By the way: the Scrum Guide by Ken Schwaber and Jeff Sutherland [19] doesn’t mention the term “task” at all.
How is it that tasks, despite a lack of clarity about their meaning, are generally associated with technical work? I assume it’s a combination of two aspects.
Firstly: No matter how you put it, every software project requires technical work to be done. And I mean real technical work, which is not related to any functionality. You guessed it: I’m talking about architectural improvements, re-engineerings, refactorings or cross-cutting infrastructural changes (such as switching to a new framework). And since there are no dedicated issue types for such kind of work, people just use Tasks.
Secondly: When breaking down User Stories or Features into smaller parts, Tasks may be created which coincidentally have no user visibility – such tasks are considered “technical” work as well.
Let me explain what I mean by coincidentally and why the tasks in the second case aren’t really technical. The way in which a functional issue is subdivided into Tasks depends on the habits, skills and personal taste of your team members – there are no definite rules, and that’s a good thing because it gives the team the freedom to organize its work in its way.
Let’s consider two possible Task decompositions of a Feature allowing the user to upload a photo to her profile with the possibility of selecting a region of the photo. The most fine-granular decomposition might require the following logical “pieces of work”:
Decomposition 1:
Decomposition 2:
The classical frontend-backend-decomposition results in one task with and one task without user visibility, consequently Task 1.2 would be commonly considered “technical”. The equally legitimate second decomposition gets along completely without “technical” tasks because each task affects the UI (i.e. describes a new behavior). That’s weird, isn’t it? For the same feature, we get different amounts of technical work. Can this be true?
No, obviously it can’t be true. This kind of view on decomposition is not correct. But not because one of the decompositions is right and the other is wrong, it’s rather because there are no real technical tasks here involved at all. The backend work in Task 1.2, which is usually classified as “technical” doesn’t represent a distinct technical concern of the system. It rather represents just an organisational concern. Task 1.2 is just a result of work-sharing, which is independent of categories such as “functional” and “technical”. The entire work associated with the implementation of a specific functionality (Feature/User Story) should be considered functional. There is no value in differentiating like crazy between functional and technical on this lower level. In particular, because it causes confusion and blurs the boundaries between real technical concerns (deserving a distinct issue type) and supporting sub-tasks of parent functional issues that just appear to be technical. At the end of the day, each coding work in itself is technical, so saying that implementing a functional issue results in some “technical” tasks makes really no sense.
The uncertainty resulting from the lack of standard issue types for technical concerns in popular issue trackers as well as the fuzzy meaning and ambiguous usage of Tasks resulted in the emergence of a somewhat strange entity called Technical User Story (or just Technical Story).
Basically, Technical User Stories just represent a distinct issue type (of an issue tracker) to be used for technical work. And as such, in the first place, Technical User Stories are a well-meant attempt to give technical concerns in software projects the visibility they deserve (see for example “TECHNICAL USER STORIES – WHAT, WHEN, AND HOW?” by Robert Galen [9]).
Unfortunately, the attempt is not courageous enough: the term “Technical User Story” alone seems like a try to hide technical issues behind functional ones, thus denying them the significance they inherently have. It is quite astonishing: don’t people see the irony behind the term? How did one come up with something so contradictory?
I think the story goes something like this: User Stories have a brilliant reputation, they are loved by scrum masters, product owners, managers, agile coaches and even customers. User Stories are the heroes of value-driven software development – they alone shoulder the entire business value of software. And so, someone must have thought, what would be more obvious than hiding technical issues under the presentable veil of User Stories. Making them first-class citizens in product backlogs and sprints, just by prepending “User Story” with “technical”. Hopefully, no one will notice.
However, the trick is pretty obvious. Consequently, quite soon, people realized that Technical User Stories are fraught with certain smells. For example, because it’s extremely frustrating to express technical concerns by using the classic “As a …, I … so that …” template. Either one ends up with monstrosities like:
or advocates of Technical User Stories argue that it’s OK not to use the classic user story formulation for technical user stories. And they are certainly right but why calling it a User Story then? Technical issues neither have end-users nor do they make up any stories – it’s that simple.
Moreover, the same advocates contribute to even greater confusion by lumping everything together (like here [9] and here [8]), when it comes to a definition of Technical User Stories. They suggest that Technical User Stories can be used for handling
That’s pretty confusing, and so people legitimately ask about the difference between Technical User Stories and Tasks and question the sense of Technical User Stories. Because of this undifferentiated approach, Technical User Stories ultimately cause more chaos and lack of understanding than they solve real problems.
Come on folks, we’re all adults. It’s not possible to improve the image of technical concerns in software projects and increase their acceptance by managers and product owners just by masking them as a special kind of User Stories. There are real compelling reasons for considering technical issues (related to technical debt, architectural improvements, refactorings, etc.) as first-class citizens of software projects. Before I get to this point, let me say a few words about the general chaos related to issue types as I see it.
Commonly, issue trackers in software projects are considered only as a kind of feature-rich To-Do list. They are used for keeping track of ongoing and planning of future tasks as well as for collaboration. And from this perspective, there is indeed little point in burdening oneself with different issue types. For the person who creates the tasks or who has to process the tasks, there is no significant difference between bugs and features or other kinds of work – there is just a list of prioritized tasks that need to be done. A bug is not automatically more important than a feature and vice versa, and for expressing “importance”, there are other means in issue trackers than issue types. The same also holds for decomposition and work-sharing – one doesn’t really need a separate issue type, such as Task or Sub-Task, in order to express parent-child relationships between issues as they are already explicitly expressed by the mere presence of the relationships themselves.
Consequently, people often feel overwhelmed by the number of standard issue types whose purposes and scopes they don’t fully understand. So instead of using issue types with confidence, they are struggling with questions such as
And because there is often not a single person in the project who can answer such questions in a consistent way, people start to search the internet, only to find out that
Does that sound familiar? If not, just have a glance on discussions such as Feature vs Task vs Story [13] and Relationship between user story, feature, and epic? [14].
The result of all this confusion is that people reduce the creation of issues to a minimum so as not to make any mistakes. Bugs are getting fixed on the fly as part of functional issues; feature implementations are polluted with cosmetic changes, refactorings disappear completely and so forth. And so, the project is losing valuable information and is getting obfuscated with difficult-to-comprehend code changes.
Tag-based issue trackers such as those available in GitLab and GitHub steer clear of the problem by not implementing the concept of issue types at all. And while it can indeed save some headache in choosing the correct issue type, such concepts usually don’t lead to more structured and disciplined approaches in projects which are necessary to leverage the full power of issue trackers.
To get the most out of issue trackers, we must consider them more than just To-Do lists to be used only for project planning. They have at least two more roles.
By now, it should have gotten through to the vast majority of developers and project managers how important the correct usage of version control systems is for the overall software quality. How important a clean and structured commit history is. That a single commit should represent only one logical and cohesive change (“atomic” commits). That a commit message should describe the what and why of a commit helping to re-establish the context of a change. That mixing unrelated changes significantly increases the cognitive effort (= WTFs per minute [15]) required to understand previous changes and change code again. And that reading and understanding (not writing) code is what developers do most of the time:
Indeed, the ratio of time spent reading vs writing is well over 10:1
— Robert C. Martin. Clean Code [1].
And that reducing this reading effort is what counts most for code quality.
If you don’t know or don’t believe that, you most probably have more significant problems than issue types in your projects. The best would be to start with the basics, such as How to Write a Git Commit Message [16] or DEVELOPER TIP: KEEP YOUR COMMITS “ATOMIC” [17] and return back here later.
Why do I mention version control systems when we are talking about issue trackers? It is because the two play in the same team and are responsible for the comprehensibility of your code. Version control systems and issue trackers belong inseparably together, and they are literally connected as soon as you start to link commits with issues – being another best practice to follow in every project.

The synergy of version control systems and issue trackers – also called code traceability – leads to a holistic view in a project, where every code change can be traced back to its ultimate “why” – the issue. And every issue identifies a set of related code changes.
From this perspective, the same (single responsibility) principles apply to issues as to commits:
Nothing is more frustrating and time-robbing than trying to understand a piece of code that has been committed under a particular issue but logically does not belong there. The issue behind a code change represents its rationale – it is the ultimate high-level explanation of the change. As developers, we tend not to doubt such explanations. We try to make sense of the change in the context of this explanation. So if someone claims to do A, but in addition is doing B and C, he’s sabotaging the comprehensibility of everything he’s doing. Mixing unrelated changes under the same issue is like willfully inserting wrong comments into the code – there is hardly a more effective way to obfuscate the sense of code.
As developers, it is our responsibility always to be aware of the reasons behind code changes. We must be absolutely disciplined in this respect. Otherwise, we’re groping in the dark and wreaking havoc. In this context, issue types are a powerful concept for keeping reasons for code changes apart. They create a mental model in our minds that helps us to reason about the cohesiveness of code changes in the right way. If there is just no issue type for refactorings, the temptation is quite high to obfuscate feature implementations with unrelated code improvements. If there is no issue type for defects, bug fixes will be done on the fly much more often, and so on. And all these spontaneous changes will not only make it difficult to understand the implementation of the “main” issue, but their own reasons will also remain largely undocumented because they won’t be expressed in separate issues. If corresponding concepts are missing, people neither won’t feel that they’re doing anything wrong nor do they have any indications for how to do it right.
In a nutshell: Code changes have reasons. And these reasons are of different kinds. Not explicitly modelling these kinds as issue types in the right way will significantly increase the probability of chaotic code changes. The existence of issue types forces us to make conscious decisions about what we do. Such decisions are often not trivial, but they are necessary, and they pay off. Sorry, pal, but that’s the way it is.
A lot has been written about the fact that software architectures don’t represent final solutions but rather solution approaches that need to be continuously adjusted as the project progresses and new requirements come up. Check out “Architecture with Agility” by Kevlin Henney [3] for a great contribution to this topic. Tom Gilb has boiled it down to the essence:
Architecture is a hypothesis, that needs to be proven by implementation and measurement.
— Tom Gilb
So basically this means that software architectures evolve within feedback loops – that’s nothing new. However, efficient feedback loops require knowledge to identify existing problems, assess the effects of past measures and to make decisions for the future. In many projects, such knowledge is based just on gut feelings to a great extent. This is a quite weak form of measurement. If we are honest, it’s not measurement at all. In this context, issue trackers can provide valuable data which can be used for measurements that matter.
The “behavior” of software architecture with respect to feature implementations is the ultimate benchmark for the quality of this architecture (just paraphrasing Tom Glib). I.e., the effort required to introduce new features into a system with a “good” architecture is approximately proportional just to the complexity of the features and not to the complexity of the whole system.
To put it in simple words: a good architecture allows for a high feature throughput without technical improvements and bugs gaining the upper hand. The only way to reliably identify such trends is to explicitly track the effort of these types of development work. If you don’t, you will lose important information that is necessary to address a whole range of significant questions, validate certain expectations and draw conclusions. You will not be able to recognize essential coherences, such as the following:
By now, there should be two questions left: How to track different types of development work and what is “effort”? The answer to the first is simple – you guessed it: issue types.
As to the effort: There is no room here to go into detail; however there are different approaches:
If you’ve read this far, it should be no secret that I strongly support the idea that refactorings should be made as explicit as possible. And that they deserve their own issue type because of this. I have already mentioned some arguments. At this point, I would like to add a few more and discuss counter-arguments I have come across on the Internet and in customer projects.
There are two dangerous and unfortunately widespread misconceptions that reinforce each other:
The funny thing is that the advocates of these views usually do not question the importance of technical debt and refactorings in general. On the contrary: they strongly believe that technical debt in agile projects should be handled on a regular basis. Unfortunately, they draw a completely wrong conclusion from this belief. Namely, that developers should do refactorings on the side as part of a user story implementation, virtually invisible. This conclusion is wrong for several reasons:
Reason 1:
Most refactorings that have a real significance to the project cannot be handled with The Boy Scout Rule:
If we all checked-in our code a little cleaner than when we checked it out, the code simply could not rot.
— Robert C. Marin. Clean Code [1].
A lot of refactorings require wide-ranging changes that might affect a lot of concepts of the architecture. The changes might even imply some re-engineering of parts of the system. This is neither something a developer can and should decide on his own, nor is it something that can be handled with an imperceptible effort on the side. These kinds of changes just cannot be broken down into a series of minor Boy-Scout-Rule-like improvements and managed unnoticed, distributed over a certain number of user stories. These changes must be documented, decided, prioritized, implemented, reviewed and often also tested. That is: made visible to the greatest possible extent.
(By the way: this is no criticism of the Boy Scout Rule.)
Reason 2:
Refactorings should never belong to a functional issue or be implemented just for a single product feature. It’s true that architectural problems often become apparent during a feature implementation. However, we should treat such insights as opportunities to learn and to understand the general shortcomings of our architecture. Consequently, the aim of a refactoring should not just be to facilitate the implementation of the current functionality but also the implementation of functionalities in the future. The current issue is just the trigger for the refactoring but not its ultimate rationale. Consequently, it’s just misleading to implement a refactoring as part of a user story.
Reason 3:
Technical Debt often occurs not inadvertently but is more often than not the result of prudent and deliberate decisions: “We must ship now and deal with consequences”. So if the origin of the debt is prudent and deliberate, why on earth would anyone want to hide its rectification behind a random user story? Thus, denying the reasonability of the initial decision to take the debt. It just doesn’t make sense.
Reason 4:
As already mentioned in the two previous sections: mixing functional and technical improvements leads to difficult to understand code and deprives the project of essential data which can be used to influence software quality.
It is undeniable that quality assurance has a business value. As a customer, I am always aware that part of my money is used for quality assurance – no matter in what form. Refactorings are quality assurance, and software projects without refactorings are not imaginable. So what are all these philosophical discussions about?
What is the point of hiding refactorings from those who have to provide the budget for them (product owners, managers)? Just stop treating software projects as “feature factories”. Accept the fact that there are technical issues in a software project that don’t have anything to do with functionality. Let us stop pretending that technical debt is solely the result of bad coding. That it’s a personal mistake of a developer/the team, not having done it right the first time. It’s not fair, not true and not honest.
Who benefits if technical debt is understated and refactorings happen in secret? Let’s not celebrate the SNAFU Principle [18] in software projects:
The effect of the SNAFU principle is a progressive disconnection of decision-makers from reality.

SNAFU in a Feature Factory
By now, we have enough knowledge and also the appropriate terminology to deal with technical debt at eye level, as engineers and even as managers:
A particular benefit of the debt metaphor is that it’s very handy for communicating to non-technical people.
— Martin Fowler. Technical Debt Quadrant [5]
So, if debt is the metaphor to make software development comprehensible to non-technical people, e.g. managers, customers, why should we hide the concept, not monitor its effort and its effectiveness by dealing with it in an explicit way as issues of an own issue type? Is there any convincing argument not to talk honestly as equal instead of superior and subordinate between customers, managers, product owners and engineers by using a mutually agreeable language?
I recently attended an interesting talk by Dr. Gernot Starke at the OOP Conference 2020 [6]. He even suggests having a separate issue type “TechDebt” which can be used to capture and document technical debt as soon as it arises. It is up to each individual to decide whether or not to implement this approach in his or her project. But such ideas reflect precisely the right mindset to handle technical debt: it should be explicit and visible to everybody.
At this point, the required issue types should no longer be a secret. I have already mentioned them in one way or another. Nevertheless, let me systematize what has been said.
The sense of every software project is to provide features to end users. Even if you’re developing a framework to be used by other developers. A new API in your framework is a feature to its end-users.
So every project needs at least one issue type for features. If you’re in a Scrum-based project, the usually used issue type is User Story. If you’re not using Scrum and/or are not bound by special naming conventions, I would use the most obvious name for this issue type, namely: Feature.
Please don’t feel compelled to use more than one issue type for functional changes unless you see a clear added value in them that helps your project to solve problems. If in doubt, start with one issue type and add more later. Don’t be afraid to remove default issue types provided by your issue tracker if you cannot define clear rules when to use them. And please be consequent: remove the types immediately, don’t keep them for later, just in case you get the sense at some point. Most probably you won’t. But as long as they exist, they will confuse you and others and cause you to waste cognitive effort. Free yourself from this burden as soon as possible.
I would like to make it explicit once again:
Do we need a separate issue type to capture changes related to issues like improving the performance or the memory footprint, handling portability and security issues, supporting new platforms, protocols etc.? Not necessarily, unless for some reasons you need to explicitly track the effort related to the implementation of these kinds of work.
Logically, operational requirements are features of your product. Even though the classical requirements engineering [7] regards them as non-functional. But it doesn’t mean that one can not have functional and non-functional features. They are features because they have a perceptible impact on your software. If an operation can be executed faster than before, the customer will notice. If you port your software to a new platform, it’s an extraordinarily large feature because it makes the entire feature set of your software available for a bunch of new users. Implementing operational requirements is neither waste nor maintenance effort or just technical work. Operational requirements add value to your software and therefore are features.
That’s easy. You need a separate issue type to handle errors and unexpected behavior. And the best name for it is Bug. The number of bugs is an important quality metric of your system; fixing bugs is an important quality assurance measure. So you better keep an eye on the bugs. Pure bug trackers (such as Bugzilla) are the ancestors of today’s full-featured issue trackers. Bugs have always been essential, and this has not changed until today.
So there’s not much to say about that. Nevertheless, there is one crucial piece of advice in this context: Be honest to yourself and do not fix bugs on the fly.
When working on a feature or a refactoring, it can happen that we find a bug by chance not noticed before by anybody. For example, because it becomes apparent to us just by looking at the code. Or a test added for a new feature fails and by tracing the reason we come across the bug. Especially if the fix would be tiny, maybe even just a one-liner, the temptation is great, not to make a big fuss about the bug and just fix it silently as part of the current issue. Even if it saves time at first glance, it isn’t a good idea. As we know, mixing unrelated changes under an issue is a bad practice. In addition, by making the bug disappear undocumented, we deprive the project of valuable information (traceability and monitoring).
Please be disciplined and create a Bug issue for every bug you discover. The time overhead is minimal, but your coworkers and your future self will thank you for it. And by the way: a bugfix is almost never a one-liner – as every bug should be covered by a test.
We need a separate issue type to capture architectural improvements, handling work related to the reduction of technical debt, performing system re-engineering and the like. For the sake of simplicity, you can call this issue type just Refactoring. Other names such as Architectural Improvement are fine as well. However, because of the inherent problems described in the first part, I do not recommend using Technical Story or Architecture Story.
The distinguishing characteristic of these types of development work is their purpose to make code improvements aiming to reduce the cognitive effort for implementing new features, reduce the probability of bugs and misconceptions of code. Here are some examples:
By the way, the implementation effort is not a distinguishing characteristic for a refactoring. Refactorings can be big or small. If you’re working on a feature and you notice that there is some computation already used at two different places and the current feature requires it a third time, a wise decision would be to source out this computation into a separate function to avoid code duplication. Even if this computation is minimal, such as computing the volume of a sphere, it’s still a refactoring. And the best approach would be to stop your current work for a moment, create a Refactoring issue briefly describing the what and why, implement it by adding the new function and adjusting the two existing locations to use it. Afterwards, you can continue with the feature implementation, which can use the new function now. A possible alternative could be to add the new function as part of the feature implementation and create a Refactoring issue to adjust the two existing locations for later. However, under no circumstances should you make these unrelated adjustments under the current feature.
Besides refactorings, there are other types of technical work in software projects that deserve an own issue type. And let’s the cat out of the bag right now: I suggest using the name Task for them. Simply put, these are all other kinds of developmental requirements [4] which are not refactorings. However, this definition is not very helpful, so let me be more precise. I think there are some categories of Tasks:
This category includes work such as upgrading to new library/framework/language versions or switching to other technologies. You might have noticed from the last section that a switch to a different technology could also be a refactoring. Whether it’s a Task or a Refactoring depends on the reason. It’s a refactoring if you aim to use new kinds of functionality of the new technology, which will help you to implement new features. In other cases it’s just a Task, e.g.:
This is the most complicated category of Tasks because the distinction to refactorings can be fluid. It’s hard to give a rock-solid definition. However, let’s start with some examples.
Imagine you decided to establish (or change) code style guidelines in your project and to reformat the existing code. Either at once or step by step. It’s fine to express it as a Refactoring because most probably there are good reasons behind this decision, aiming to increase code readability. After the refactoring is done, you expect your developers to comply with the new guidelines and only produce code according to the new style. So all the future style violations that require fixes are not refactorings anymore, they should be handled under Tasks. It’s avoidable waste resulting either from lack of discipline, poor communication, bad tooling or carelessness. You better reduce this kind of effort to a minimum in your project. Same holds for fixing of typos.
Another category of avoidable waste are fixes related to unstable or otherwise problematic tests. Usually, proper tests should be committed together with the main issue implementation (feature, bug, even some refactorings could require tests). If these tests start to make problems (e.g. because they fail randomly), the additional effort can be regarded as waste.
In general, changes related to bad coding practices (such as using a deprecated function with security holes) that require fixes, can be regarded as avoidable waste as well.
I apologize for this category. However, there are just some miscellaneous cases like adding/modifying copyright comments which should also be handled under Tasks.
Unfortunately, there are also some less obvious cases. For example, improving/adding documentation or adding new or improving existing tests.
Sometimes when trying to understand code, you might come across a construct with no or poor documentation, so you spend some time to understand it. In the end, you might feel inclined to express the new insights by adding documentation. So what to do? Given that documentation improves the comprehensibility of code and thus potentially reduces the cognitive effort to understand code, documentation improvements can be regarded as refactoring-like changes. On the other hand, one could argue that adding proper documentation should have been done right from the start, so improving it is rather maintenance effort.
To make the right decision, it always helps to remember why a distinction between refactorings and maintenance is necessary at all. The keyword is: monitoring (see section “Issue Trackers as Basis for Quality”). We’re interested in separately capturing refactoring work, in order to evaluate the effectiveness of our refactorings. After a certain amount of refactoring effort, we expect the feature throughput to increase and/or the bug effort to decrease. This is something that we don’t immediately expect from maintenance work. Nevertheless, we’re still interested in separately capturing the effort for maintenance because the goal should be to reduce as much as possible. If we’re spending too much time configuring our tools, fixing version conflicts between libraries or improving code style instead of implementing features, something is wrong in our project, and we should pivot.
Creating a separate ticket for every small problem (such as: fixing a typo or wrong indentation or removing an obsolete import) encountered during coding is not feasible. However, we don’t want to violate the overall rule not to mix unrelated changes. How can we address this challenge?
We at Cape of Good Code use a concept which we call “Never-Ending Issues”. These are just regular issues in our tracker, but they are not intended ever to be closed. They are used to commit small refactoring-like and maintenance changes. So the most straightforward approach is to start with two never-ending issues: one Refactoring and one Task.
Never-ending Refactorings can be used to commit things like renames of identifiers to make them more expressive, for small documentation improvements or for occasionally removing unused code.
Never-ending Tasks can be used for small cosmetic changes and other types of small maintenance changes.
If you’re not comfortable with the “never-ending” concept, you can create such issues for small, occasional changes per sprint/release/month/year and close them afterwards.
However, the scope of such never-ending issues should be reserved just for small changes that don’t deserve an own issue. You should pay attention that never-ending issues are not misused in your project. They are an excellent compromise, but should not be used to throw rules overboard.
So far, we have four issue types: Feature/User Story, Bug, Refactoring and Task. Are they sufficient to implement the concept of task-decomposition, i.e. breaking down bigger issues into smaller sub-tasks? Well, yes and no.
To be honest, I like Jira’s idea of Sub-Tasks. Having a separate issue type for decomposition avoids confusion and makes it clear that the corresponding issue is meant just for breakdown. In particular, logically Sub-Tasks don’t have an own issue type – they “inherit” their type from their parent. Don’t get me wrong: “type inheritance” isn’t something that is technically implemented in Jira. It should be rather our mental view on Sub-Tasks, meaning that the effort spent on a Sub-Task of a Bug should be counted as Bug-effort, the effort for a Sub-Task of a Feature is Feature-effort etc. It isn’t particularly useful to track the number of Sub-Tasks or the effort spent on Sub-Tasks as a separate metric.
However, could we get along also without Sub-Task? Theoretically yes. By using Tasks instead. That way, Tasks would have two different purposes. If a Task appears as a child of another issue, it has all the properties of a Sub-Task, in particular no own issues type. If it appears as a standalone issue, it should be treated as maintenance effort. In this scenario, we could end up with Tasks having other Tasks as children. You see, this solution has a lot of potential for confusion. And by the way, this is nothing that is supported per default by Jira because Tasks cannot be children of other issue types except of Epics. So I clearly advocate the solution with Sub-Tasks.
Sometimes you know ahead that you’re going to implement multiple features which are going to share a common infrastructure, such as common database tables or a new communication protocol. So you create a separate issue to implement these technical aspects. Either to explicitly express that the infrastructure is used by both features and/or to structure the solution and/or because the corresponding implementation work will be taken over by a separate person. And while these are all legitimate reasons for a decomposition, we can quickly run into a problematic situation. The following example shows two common ways to express such a breakdown: with and without Epics.
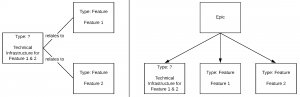
Bad ways to express technical infrastructure work related to multiple features.
The problem results from the fact that technical infrastructure added to the code base to implement certain features should be counted as Feature-effort and not as something else. However, it’s not easily possible to express this with our current set of issue types and the above decomposition. If we use a Sub-Task for the infrastructure issue (which is not possible per default in Jira because Epics cannot have Sub-Tasks), we have no way to derive its logical type because it’s not connected to any Feature. Consequently, we would need an additional issue type, such as “Feature-Sub-Task” in order to model the above scenario.
Fortunately, there is a better solution which doesn’t unnecessarily complicate our issue types model.
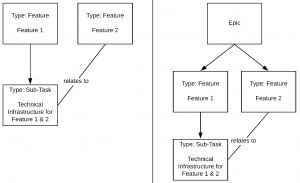
Correct ways to express technical infrastructure work related to multiple features.
We can just make the technical infrastructure issue be a Sub-Task of one of both features. Optionally we can use a separate relation to express that the other feature also uses the infrastructure.
At first glance, it may seem like an arbitrary solution because the effort for the technical infrastructure will be attributed just to one of the features, even though it logically belongs to both. However, this is a fallacy. It is the usual case in every project that an arbitrary number of features reuses technical infrastructure added for one feature in the past. Nobody is supposed to identify the first issue under which the corresponding infrastructure was added to the code base just to create a corresponding relation. The above case is rather an exception because coincidentally we know of two features at the same time that rely on the same infrastructure. Explicitly modelling this fact through relations is a nice-to-have but certainly nothing we should give too much attention to. So, whenever you do task breakdown, keep in mind that type of effort to be attributed to child issues should be derivable from their parent issues.
If you’re using the issue tracker to track all kinds of work in your software development project, then most probably you will have tasks which don’t immediately result in code changes. It could be organizational tasks, such as onboarding of new coworkers or other types of work, such as doing technology evaluations. Which issue types should you use for this work? Well, if you want to capture these tasks in the same issue tracker project as the development work, you can choose any types you wish to. They are not relevant for the considerations described here; they are not part of the model in question. The model cares only about issues which can be associated with code changes.
You could even use Tasks for such kind of work. With the following mental rule: Tasks with code changes are maintenance work, Tasks without are everything else.
The most practical takeaway is that every software development project needs at least four main issue types:
It might be surprising that we ended up with two types for technical and only one for functional work. In many projects, it is rather the opposite: there are multiple types for functional work and only one or no types for technical work. Actually, it is logical because functional requirements are simple, accepted and well-understood, handling them doesn’t require deep insights:
Functional requirements are typically binary in nature: you either meet a requirement or you don’t. There are no shades of grey, no extra-Boolean possibilities lurking between true and false. It either passed or it failed. That’s the nice thing about functional requirements. They are precise. There is no approximation.
— Kevlin Henney. Inside Requirements [4].
In this post, I have ventured into the less clear and precise things and tried to provide structural insights about technical issues by pointing out their significance in software projects. In particular, I have tried to reason why technical debt deserves maximal visibility.
When researching for this post, I came across an interesting paper: Requirements Communication in Issue Tracking Systems in Four Open-Source Projects [2]. By analyzing natural language communication in issue trackers, the authors tried to categorize issue types logically represented there. These are the results:
The following issue types were discovered: 1) Feature-Related – information, related to a new software feature or software requirements, 2) Bug-Related – software failures and problems, 3) Refactoring-Related – software changes that neither affect the functionalities nor the qualities of the software (besides maintainability), 4) SE Process-Related – discussions about the general SE process, e.g. if a developer notices that tests should be run more frequently in the project or if documentation should be relocated,..
Our four suggested issue types are virtually congruent with the ones identified in the natural language. I think the findings are quite impressive: they show that these four issue types represent inherent concerns and types of development work. This is another confirmation that the suggested differentiation is fundamental.
But enough talk, let me finish with a list of clear rules.
What do you think about this approach? Do you see any edge cases that don’t fit into this model? Let me know. I’m Looking forward to discussing them. Feel free to provide any comments below.
White Stripes on the Tail Put Maschine Guns of a Fighter Plane Out of Action - A Technical Debt Story
Git squash merge doesn't really help to produce clean commit histories. It's just a crutch to hide the inability to split commits in a reasonable...
10 rules & best practices your supplier should absolutely follow if they want to be listed as a stress-free supplier to their customers.