Einer unserer Entwickler postete kürzlich in unserer Firmen-Chat-Gruppe eine Link zu einem Blogartikel mit dem provokanten Titel “Git Commit Messages are useless” und fragte, was wir davon hielten.
Nun, wie zu erwarten war, hat der Autor nicht wirklich die Sinnhaftigkeit von Commit-Messages an sich in Frage gestellt, sondern nur solcher, die häufig auf Feature-Branches entstehen, wenn Entwickler zufällige Stände ihrer Arbeit zwischenspeichern. Und weil dabei sehr viele wenig-aussagekräftige Commit-Messages und inkonsistente Commits entstehen, die eher verwirren, die Historie verschmutzen und nicht zur Verständlichkeit beitragen, sollte man squash merge verwenden, um aus dem ganzen Chaos auf dem Feature-Branch einen einzigen Commit auf master zu bauen.
Womit man mit dem Squash-Merge-Ansatz dann bei einem Commit pro PR landet (mit einer Message, die dem Titel des PRs entspricht), eine saubere Historie hat und sich beruhigt auf die Schulter klopfen kann.
Es wäre schön, wenn es so einfach wäre. Ist es aber nicht.
Squash merge is just the lesser of two evils
Eine kurze Erinnerung, was Squash-Merge eigentlich macht:
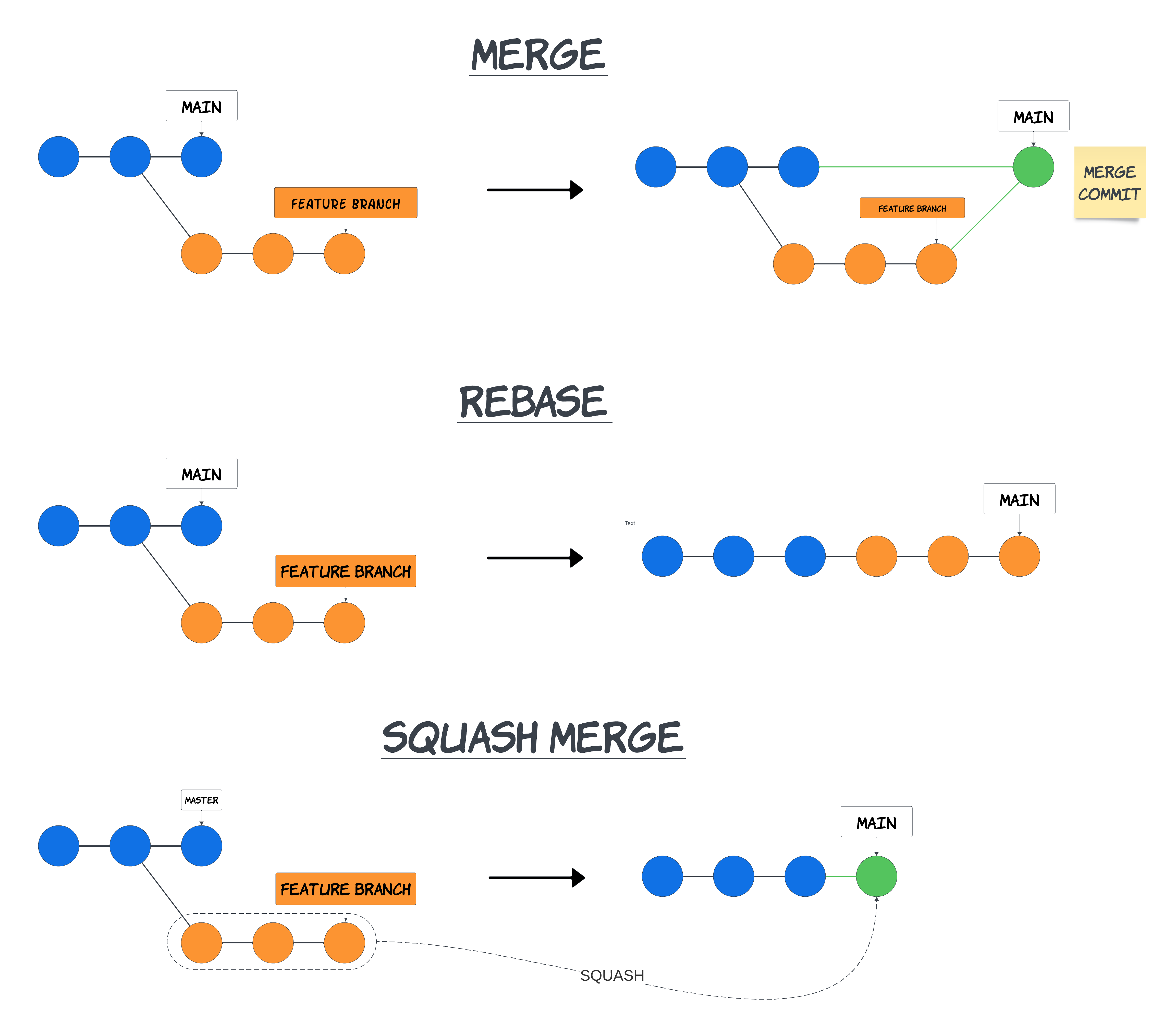
Beim Squash-Merge werden alle Commits aus einem Feature-Branch (orange) zu einem Commit zusammengefasst und dieser Commit wird auf Master (grün) rebased. Die ursprünglichen Commits auf dem Feature-Branch werden entfernt.
Keine Frage: Ein Commit pro PR/Feature/Bug ist besser als ein Haufen chaotischer Zwischenstände, die eher den Tagesablauf des Committers und seine zufälligen Gedankengänge widerspiegeln, als die Logik der Änderungen in Bezug zum Requirement und der Codebase.
Aber damit läuft man nur von einem Extrem ins andere. Die Wahrheit liegt wie immer in der Mitte. Denn zwischen totalem Chaos und dem totalen Chaos zusammengequetscht in einem Commit gibt es noch den besseren Weg, sich die Mühe zu geben, eine große Gesamtänderung auf mehrere leicht-nachvollziehbare aufzuteilen. Es ist bloß eine weitere Art von Modularisierung - und zwar auf Commit-Ebene. Jeder, der schon mal Commit-Historien gelesen oder Code reviewed hat, wird es bestätigen können. Dazu ist schon sehr viel geschrieben worden. Z.B. How to Write a Git Commit Message oder Make Atomic Git Commits.
Falls das menschliche Gehirn in den letzten paar Jahren sich nicht plötzlich evolutionär weiterentwickelt hat und die Fähigkeiten des Kurzzeitgedächtnisses sich nicht wesentlich verbessert haben, gibt in Bezug auf die Vorteile von “kleinen Häppchen” nichts in Frage zu stellen. Lies das, wenn Du mir nicht glaubst: Millersche Zahl:
Die Millersche Zahl bezeichnet die von George A. Miller 1956 beschriebene Tatsache, dass ein Mensch gleichzeitig nur 7 ± 2 Informationseinheiten (Chunks) im Kurzzeitgedächtnis präsent halten kann
Ein Commit pro PR oder Issue ist zu wenig
Außer in trivialen Fällen und bei kleinen Bugfixes, entsteht die Implementierung eines Features durch mehrere in sich geschlossene, logische Änderungen.
Bei der Aufteilung der Implementierung auf leicht-verständliche Happen geht es nicht darum, auf eine schulische Art und Weise den Lösungsweg zu demonstrieren (wie der Autor behauptet), sondern darum die Nachvollziehbarkeit zu erhöhen, indem man jeder Änderung einen sinnvollen Kontext mitgibt. Das verbessert die Nützlichkeit von Reviews und die Coververständlichkeit. Und das ist nachgewiesenermaßen so. Beispielsweise in die folgenden Studien:
1. Code Reviews Do Not Find Bugs by Microsoft
Code review usefulness is negatively correlated with the size of a code review. That is, the more files there are in a single review, the lower the overall rate of useful feedback.
Im Umkehrschluss: kleiner Commits führen zu besseren Reviews.
2. Modern Code Review: A Case Study at Google
At Google,
Over 35% of the changes under consideration modify only a single file.
About 90% modify fewer than 10 files.
Over 10% of changes modify only a single line of code.
The median number of lines modified is 24.
Wie kann man diese wünschenswerte Verteilung erreichen, wenn man ständig ganze Branches in einen einzigen Commit squashed?
Darf ich jetzt meine Zwischenstände nicht auf einem Feature Branch speichern?
Natürlich darfst Du! Auf einem Feature Branch darfst Du alles tun, was Du willst, solange Du es nachträglich (bevor es reviewed wird und auf master kommt) in eine saubere und logische Reihenfolge bringst. Fürs Commiten gilt das gleiche wie für Clean Code:
First make it work, then make it right.
-- Kent Beck
Und Git bietet mit Interactive Rebasing und Interactive Stagingmächtige Werkzeug für dieses nachträgliche Saubermachen. Mach Dich damit vertraut. Höchstwahrscheinlich kann ein UI-basiertes Git-Werkzeug Deiner Wahl die Nutzung dieser Funktionalitäten sogar noch viel einfacher machen. Ich bin sehr zufrieden damit, wie es in TortoiseGit (Commit only parts of files) implementiert ist.
Warum wird Squash-Merge trotzdem immer populärer?
Nun, ganz einfach, weil Plattformen wie GitHub oder Gitlab es als Feature eingebaut haben. Es ist aber nicht alles Gold, was glänzt.
Für manche Entwicklungs-Verantwortlichen erscheint es wie ein Segen. Eine Möglichkeit, die Faulheit oder Unfähigkeit ihrer Entwickler oder ihr eigenes fehlendes Überzeugungsvermögen auf eine vermeintlich geschickte Art und Weise zu kaschieren.
Und das ist nicht etwa eine Phantasie von mir. Wir hören so etwas häufiger in Projekten:
Ich kann meine Entwickler nicht zwingen, gute Commit-Message zu schreiben, die haben ohnehin schon viel zu tun.
Meine Entwickler können keine freie Texte schreiben.
und ähnliche Ausreden.
Falls euer Entwickler das nicht können, überlegt euch, ob ihr solche Entwickler überhaupt an Board haben wollt. Wenn jemand seine Gedanken in natürlicher Sprache nicht strukturieren und aufschreiben kann, so dass sie für andere verständlich sind, kann man dann von ihm erwarten, dass er selbsterklärenden Code schreiben kann? Rhetorische Frage...

Jason Fried & David Heinemeier bringen es auf den Punkt in ihrem Buch ReWork: Change the Way You Work Forever:
Hire great writers.
Kommt schon Leute, seid ehrlich zu euch. Ihr wisst, dass es nicht möglich ist Probleme wie von Geisterhand verschwinden zu lassen, Chaos in Ordnung zu verwandeln mit einem Klick. Dafür braucht es Arbeit und Disziplin. Alles andere kehrt nur das Chaos unter den Teppich und schadet eurer Wartbarkeit.
Gibt es trotzdem Gründe, Squash-Merge zu verwenden?
Ganz ehrlich: eigentlich nicht. Lernt besser gute Commit-Messages zu schreiben und gebt euch Mühe, Änderungen sinnvoll aufzuteilen.
Einen “halben” Grund für Squash-Merge möchte ich dennoch nicht unerwähnt lassen. Falls man einen Commit pro PR hat, dann lässt sich ein PR im Falle eines Bugs tatsächlich einfacher reverten. Selbst wenn eine Issue-ID in jedem Commit drin steht, ist die Fehleranfälligkeit beim Reverten von mehreren Commits, um ein ganzes Feature rückgängig zu machen, tatsächlich höher.
Aber wenn Euch das Reverten so wichtig ist, dann solltet Ihr, erstens, womöglich auf einen Rebase-Workflow verzichten und stattdessen mit Merges arbeiten. Klar, eine lineare Historie müsst ihr damit aufgeben. Aber das Leben besteht eben aus Tradeoffs, Freunde. Und zweites: falls Ihr einen sauberen Workflow aufgebt, weil Ihr so häufig Reverten müsst, stimmt evtl. was grundsätzliches in eurem Projekt nicht? Evtl. mal darüber nachdenken.
Feature-Request: Git-Plattformen sollten Feature-bewusst werden
Um beide Welten zusammenzubringen - saubere, lineare Historien und einfache Reversibilität - sollten Pull-Requests und Issues zu First-Class-Citizens in einem Repository werden. Ein PR oder Issue sollte mit einem Klick rückgängig gemacht werden können, unabhängig davon, ob er aus einem oder mehreren Commits besteht und unabhängig davon, ob er zusammengeführt oder rebased wurde. Natürlich müssten dazu zusätzliche Metadaten gespeichert werden, um eine Reihe von zusammenhängenden Commits zu identifizieren. Aber im Falle eines PR-Merges oder wenn Commit-Messages Issue-IDs enthalten, sollte es nicht schwierig sein, diese Daten automatisch zu sammeln.
Zusammenfassung
- Squash Merge löst keine Probleme, es verdeckt sie nur. Es ist schädlich.
- Lernt lieber, wie man gute Commit-Messages schreibt und Commits sinnvoll aufteilt. Probiert es einfacher selbst aus oder holt Euch ein wenig Hilfe von uns in einem Training zur Entwicklungsmethodik (das auch den nächsten Punkt abdeckt).
- Macht Euch mit Interactive Rebasing and Interactive Staging vertraut
- Wenn Ihr Squash-Merge benötigen, weil Ihr häufig Funktionalitäten reverten müsst, fragen Euch, warum das so ist, und geht dann zu den die Punkten 1, 2 und 3 zurück
Quellen
- Featured Image
- Git commit messages are useless
- Squash and merge your commits
- How to Write a Git Commit Messager
- Make Atomic Git Commits
- The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information
- Code Reviews Do Not Find Bugs by Microsoft
- Modern Code Review: A Case Study at Google
- Git Tools - Rewriting History
- Git - Interactive Staging
- Committing Your Changes to the Repository - TortoiseGit
- Jason Fried, David Heinemeier Hansson (2010). ReWork: Change the Way You Work Forever.
- Training - Entwicklungsmethodik