Technical Debt
The Most ‘Striking’ Way To Explain Technical Debt – Even to Your Kids & Managers
White Stripes on the Tail Put Maschine Guns of a Fighter Plane Out of Action - A Technical Debt Story
Git squash merge doesn't really help to produce clean commit histories. It's just a crutch to hide the inability to split commits in a reasonable way.
One of our developers recently posted a link to a blog article in our company chat group with the provocative title Git commit messages are useless and asked what we thought of it.
Well, as you might expect, the author wasn't really questioning the usefulness of commit messages per se, just the ones that often occur on feature branches when developers save random states of their work. And because this results in a lot of uninformative commit messages and inconsistent commits, which tend to confuse and pollute the history and do not contribute to comprehensibility, squash merge should be used to create a single commit on master from all the chaos on the feature branch.
With the squash merge approach, you would end up with one commit per pull request (PR), with a message that corresponds to the title of the PR, a clean history and can pat yourself on the back.
It would be nice if it were that simple. But it's not.
A quick reminder of what squash merge actually does in comparison to just merging or rebasing:
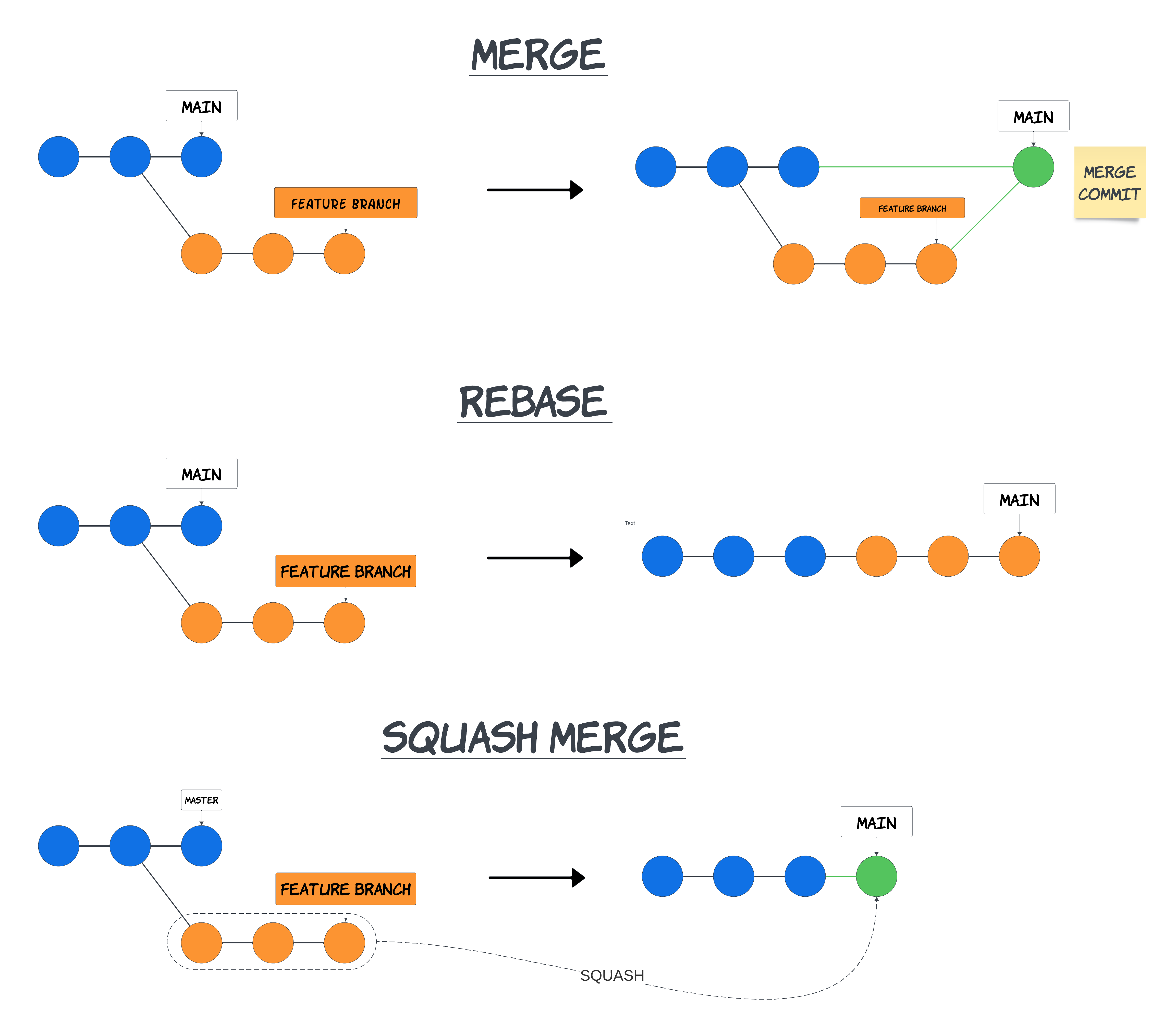
Squash merge takes all the commits from a feature branch (orange), squashes them into one and rebases this commit on master (green). The original commits from the feature branch are removed.
No question: One commit per PR/feature/bug (one evil) is better than a bunch of chaotic intermediate states (the other evil), which reflect the committer's daily routine and random thought processes rather than the logic of the changes in relation to the requirement and the codebase.
But that's just going from one extreme to the other. As always, the truth lies in the middle. Because between total chaos and total chaos squeezed into one commit, there's a better way to take the extra effort to split a big overall change into several easy-to-follow ones. It's just another kind of modularization - at the commit level. Anyone who has ever read commit histories or reviewed code will be able to confirm this. A lot has already been written about this. For example How to Write a Git Commit Message or Make Atomic Git Commits.
Unless the human brain has suddenly evolutionized in the last few years and short-term memory skills have not significantly improved, there is nothing to question about the benefits of "small bites". Read this if you don’t believe: The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information:
The number of objects an average human can hold in short-term memory is 7 ± 2.
Except in trivial cases and for small bug fixes, the implementation of a feature is the result of several self-contained, logical changes.
Splitting the implementation into easy-to-understand chunks is not about demonstrating the solution in a scholastic way (as claimed in the article), but about increasing comprehensibility by giving each change a meaningful context. This improves the usefulness of reviews and the comprehensibility of code. And this has been proven to be the case. For example in both following studies:
1. Code Reviews Do Not Find Bugs by Microsoft
Code review usefulness is negatively correlated with the size of a code review. That is, the more files there are in a single review, the lower the overall rate of useful feedback.
Conversely, smaller commits mean better reviews.
2. Modern Code Review: A Case Study at GoogleAt Google,
Over 35% of the changes under consideration modify only a single file.
About 90% modify fewer than 10 files.
Over 10% of changes modify only a single line of code.
The median number of lines modified is 24.
How can you achieve this desirable distribution if you are constantly squashing entire branches into one commit?
Of course you can! You can do anything you want on a feature branch as long as you put it in a clean and logical order afterwards (before it is reviewed and goes to master). The same applies to commits as to Clean Code:
First make it work, then make it right.
-- Kent Beck
And with interactive rebasing and interactive staging Git offers powerful tools for this subsequent cleanup. Familiarize yourself with them! Most likely, a UI-based Git tool of your choice can even make the use of these functionalities much easier. I am very happy with how it is implemented in TortoiseGit (Commit only parts of files).
Well, quite simply because platforms such as GitHub or Gitlab have it as a feature. But all that glitters is not gold.
For some development managers, it seems like a boon. A way to conceal the laziness or inability of their developers or their own lack of conviction in a supposedly clever way.
And this is not just a fantasy of mine. We hear this more often in projects:
I can't force my developers to write good commit messages, they already have a lot to do.
My developers can't write free text like that.
and similar excuses.
If your developers can't do this, think about whether you want such developers on board at all. If someone can't structure his thoughts in natural language and write them down so that others can understand them, can they be expected to write self-explanatory code? Rhetorical question…

Jason Fried & David Heinemeier Hansson put this aspect in a nutshell in their book ReWork: Change the Way You Work Forever:
Hire great writers.
Come on guys, be honest with yourselves. You know that it's not possible to make problems disappear as if by magic, to turn chaos into order with one click. It takes work and discipline. Anything else just sweeps the chaos under the carpet and damages your software maintainability.
Honestly: not really. Better learn to write good commit messages and make an effort to split changes wisely.
However, I would like to mention one "half reason” for squash-merge. If you have one commit per PR, then a PR can actually be reverted more easily in the event of a bug. Even if there is an issue ID in each commit, reverting multiple commits to undo an entire feature is actually more prone to errors.
But if reverting is so important to you, then you should, firstly, perhaps do without a rebase workflow and work with merges instead. Sure, you'll have to give up a linear history. But life is made up of trade-offs, friend. And secondly: if you give up a clean workflow because you have to revert so often, is there something fundamentally wrong with your project? Maybe think about that.
To bring both worlds together - clean, linear histories and easy reversibility - pull requests and issues should be turned into first-class citizens in a repository. A PR or issue should be revertable with one click, regardless of whether it consists of one or more commits and regardless of whether it has been merged or rebased. Of course, this would require additional metadata to be stored in order to identify a set of related commits. But in the case of a PR merge or if issue IDs are available in commit messages, it should not be difficult to collect this data automatically.
White Stripes on the Tail Put Maschine Guns of a Fighter Plane Out of Action - A Technical Debt Story
Practical guide on how to improve software quality and establish effective monitoring through the right selection of issue types.
10 rules & best practices your supplier should absolutely follow if they want to be listed as a stress-free supplier to their customers.