Das Thema ist auch als “Architektur-Hotspots aufspüren” in der Ausgaben 01/2020 von JAVAPRO erschienen. Den kompletten Artikel gibt es hier als PDF.
Einführung
Strukturelle Abhängigkeitsanalysen sind von begrenzter Aussagekraft. Teilweise erfassen sie die wesentlichen Architektur-Hotspots nicht, wie wir anhand eines Code-Beispiels exemplarisch zeigen. Die vorgestellten Konzepte zur Feature-Modularität sind eine neue Art die System-Komplexität zu erfassen. Sie zielen darauf ab, Architektur-Hotspots zu identifizieren, die den (Wartungs-) Aufwand für neue Features ansteigen lassen.
Ein weit verbreiteter Ansatz zur Bewertung von Softwaresystemen und deren Architekturen besteht in der Analyse ihrer Abhängigkeitsstruktur. Ziel ist es, Abhängigkeitsstrukturen zu identifizieren, die allgemein als schwer wartbar bekannt sind, wie zyklische Abhängigkeiten, sowie bestimmte systemspezifische Verletzungen, wie z.B. schichtübergreifende Abhängigkeiten.
Es besteht kein Zweifel, dass die Abhängigkeitsanalyse wertvolle Einblicke in die Struktur eines Softwaresystems liefert und tatsächlich echte Wartungsprobleme aufdecken kann. Trotz ihrer Nützlichkeit hat die klassische Abhängigkeitsanalyse aber große Schwächen.
Schwächen klassicher Abhängigkeitsanalysen
Sie berücksichtigt nur strukturelle Abhängigkeiten, wie z.B. Aufruf- und Import-Abhängigkeiten. Sie versäumt es, implizite Abhängigkeiten zu erkennen, wodurch verschiedene Artefakte (z.B. Dateien, Module, Klassen) gleichzeitig angepasst werden müssen, ohne dass eine sichtbare Abhängigkeit zwischen ihnen besteht.
Zudem ergibt die strukturelle Abhängigkeitsanalyse oft falsch-positive Ergebnisse. Auch wenn problematische Abhängigkeitsstrukturen sicher auf potentielle Schwierigkeiten hindeuten, müssen sie im Sinne eines erhöhten Wartungsaufwandes keine wirklichen Probleme verursachen. Die Gründe dafür können unterschiedlich sein.Hier seien paar genannt:
- Code-Module, die von schlechten Abhängigkeitsstrukturen betroffen sind, laufen stabil und werden während des Lebenszyklus eines Softwaresystems nicht sehr oft verändert.
- Die Entwickler sind sich der potentiell problematischen Stellen bewusst und berücksichtigen die Auswirkungen bei der Implementierung entsprechend, so dass unangenehme Überraschungen wie Folgefehler vermieden werden.
- Nicht jede zyklische Abhängigkeit ist für sich genommen problematisch. Einige könnten sogar absichtlich eingeführt werden, um große Module in kleinere aufzuteilen. Dabei sind die kleineren Module als Teil der Implementierung und weniger als Teil des Designs der Architektur anzusehen.
Im Allgemeinen versucht die klassische Abhängigkeitsanalyse Fälle einer engen Kopplung aufzudecken. Dabei bleibt sie jedoch oft zu fein-granular und kurzsichtig und lässt das große Ganze außer Acht. In realen Systemen können strukturelle Kopplungen zwischen einzelnen Code-Modulen oder deren Fehlen nicht als ausreichende Bedingungen für eine schlechte bzw. gute Wartbarkeit angesehen werden.
Es besteht kein Zweifel, dass das Vorhandensein einer engen Kopplung ein starker Indikator für Probleme bei der Wartbarkeit ist. Diese Zuversicht folgt auch aus der Erfahrung. Es scheint jedoch, dass allein die Betrachtung struktureller Kopplungen zwischen einzelnen Code-Module zu ungenau ist. Welche Art von Kopplung ist also im Hinblick auf die Wartbarkeit wirklich wichtig?
Von der Modul-Kopplung zur Idee der Feature-Kopplung
Die Beantwortung dieser Frage erfordert eine Definition der Wartbarkeit. Eine einfache könnte sein:
Der Aufwand, der erforderlich ist, um neue Funktionalitäten in ein wartbares System einzuführen, ist ungefähr proportional nur zur Komplexität der Funktionalität und nicht zur Komplexität des gesamten Systems.
Um es in einfachen Worten auszudrücken: In einem wartbaren System sollte es nicht der Fall sein, dass die Implementierung neuer Funktionalitäten, die wir im folgenden Features nennen, immer schwieriger wird und immer mehr Zeit in Anspruch nimmt. Umgekehrt bedeutet dies, dass ein System unabhängig von der Qualität seiner Abhängigkeitsstruktur (oder möglicherweise anderer Metriken) als wartbar zu betrachten ist, solange der durchschnittliche Aufwand pro Feature nicht weiter steigt. Wen kümmert eine enge strukturelle Kopplung und zyklische Abhängigkeiten, sofern sie nicht den gesamten Entwicklungsprozess verlangsamen? Und was ist eine strukturelle Modularisierung mit einer schönen Abhängigkeitsstruktur wert, wenn man immer beständig Projekttermine verpasst?
Ein genauerer Indikator für den potentiellen Grad des Aufwands für die Einführung neuer Funktionalität in ein System muss gefunden werden. Und dieser Indikator sollte sich wohl am besten auf die Features und deren Implementierung fokussieren. Features sind als Hauptbausteine von Softwaresystemen zu behandeln – und nicht Code-Module, Dateien oder Klassen. Es ist zu erwarten, dass die Analyse und Verbesserung der Beziehungen zwischen Features, und nicht zwischen Code-Modulen allein, genauere Aussagen über die Wartbarkeit eines Systems ermöglicht.
In der Regel kann ein Feature in einem System umso schneller implementiert werden, je weniger umgebender Code verstanden, geändert und erneut getestet werden muss und je weniger “unverwandter” Code, der für andere Features verantwortlich ist, betroffen ist. Je weniger sich eine Feature-Implementierung mit anderen Feature-Implementierungen überschneidet und diese möglicherweise “stört”, desto eher ist es wohl möglich, sie in einer angemessenen Zeit zu implementieren, ohne die bestehende Funktionalität zu beeinträchtigen.
Der Grad der Schnittmenge eines Features mit anderen Features im Code wird hier als Feature-Kopplung verstanden. In diesem Zusammenhang kann ein Feature als Folgendes erachtet werden:
- Eine von Menschen lesbare Beschreibung der erwarteten Funktionalität, der eine eindeutige ID zugewiesen wird. Normalerweise werden Features in Issue-Tracker-Systemen gepflegt und als Tickets mit entsprechenden Ticket- oder Issue-IDs ausgedrückt.
- Ein Satz von Commits in ein Versionskontrollsystem, die erforderlich sind, um die notwendigen Code-Änderungen einzuführen, die die Funktionalität des Features ausmachen.
Um die Feature-Kopplung programmatisch analysieren zu können, muss jeder Commit, der zu einem Feature gehört, mit der entsprechenden Feature-ID verknüpft werden.
Die diskutierten Ideen sollen im folgenden skizzierten Code-Beispiel veranschaulicht werden. Wir haben der Einfachheit halber im Folgenden User Stories als Tickettyp zur Aufnahme der Features spezifiziert.
Feature-Kopplung an einem Code-Beispiel
In diesem Abschnitt werden wir ein Beispiel skizzenhaft in Java implementieren. Es geht darum, Objekte in der realen Welt zu erkennen und sie auf lustige Weise zu dekorieren. Zu diesem Zweck hat die Software Zugriff auf eine drehbare Kamera. Für den ersten Meilenstein sind die folgenden User Stories zu implementieren:
- User Story #1: Der Benutzer möchte vom System erkannte Autos lustig dekorieren (Lustige Autos)
- User Story #2: Der Benutzer möchte vom System erkannte Personen lustig dekorieren können (Lustige Personen)
Abkürzend referenzieren wir im Folgenden an machen Stellen User Story #1 als das Feature “Lustige Autos” und User Story #2 als “Lustige Personen”. Als Teil von User Story #1 wird Skeleton-Code für die Darstellung und Wahrnehmung der Welt erstellt. Es werden zwei neue Dateien hinzugefügt: WorldModel.java und WorldParser.java
Listing 1: WorldModel.java mit Commit 1
import WorldObject
import Observer
public final class WorldModel {
public enum EventType {}
private HashMap<EventType, List<Observer>>
eventObserverMap = new HashMap<>();
public WorldModel() {
}
public void subscribe(Observer observer, EventType event) {
var observerList =
eventObserverMap.getOrDefault(event, new ArrayList<>());
observerList.add(observer);
eventObserverMap.put(event, observerList);
}
private void notify(EventType event, WorldObject obj) {
var observerList =
eventObserverMap.getOrDefault(event, new ArrayList<>());
observerList.forEach(observer -> observer.onEvent(event, obj));
}
}
Listing 2: WorldParser.java mit Commit 1
import Frame
import Camera
import WorldModel
public class WorldParser {
private Camera cam = new Camera();
public WorldParser() {
}
public void mainLoop() {
while (true) {
processFramesFor10Seconds();
cam.rotate(45);
}
}
public void processFramesFor10Seconds() {
var iterator = cam.getFrameIterator();
while (iterator.hasNext()) {
parseFrame(iterator.next());
}
}
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
}
private byte[] lowLevelProcessing1(Frame frame) {
// retrieve first-level raw data
...
}
...
}
Die WorldModel-Klasse dient als Container von Objekten, die derzeit in der Welt repräsentiert werden, und implementiert das Observer-Muster, um bestimmte Ereignisse im Zusammenhang mit diesen Objekten zu verteilen. Die WorldParser-Klasse beobachtet die Umgebung durch Drehen der Kamera, um konkrete Objekte zu erkennen. Die nächsten drei Commits implementieren die Funktionalität hinter User Story #1, womit sich sukzessive folgendes Bild des Codes ergibt:
Listing 3: WorldModel.java mit Commit 2
public final class WorldModel {
public enum EventType { CAR_APPEARED }
private ArrayLis<Car> cars = new ArrayList<>();
...
public void addCar(Car car) {
cars.add(car);
notify(EventType.CAR_APPEARED, car);
}
}
Listing 4: WorldParser.java mit Commit 3
public class WorldParser {
...
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
var car = findCar(data3);
car.ifPresent(value -> WorldModel.getInstance().addCar(value));
}
private Optional<Car> findCar(byte[] data) {
...
}
}
Listing 5: FeatureFunnyCar.java mit Commit 4
public class FeatureFunnyCar extends Observer {
public FeatureFunnyCar() {
WorldModel.getInstance().subscribe(
this, WorldModel.EventType.CAR_APPEARED);
}
@Override
public void onEvent(WorldModel.EventType event, WorldObject obj) {
makeFunnyCar((Car)obj);
}
private void makeFunnyCar(Car car) {
...
}
}
Nun wird User Story #2 (Personen lustig dekorieren) ebenfalls mittels sehr ähnlicher drei Commits umgesetzt, so dass sich am Ende zusätzlich zum neuen Code-Modul FeatureFunnyPerson.java folgendes Bild des Codes hinter WorldModel.java und des WorldParser.java ergibt:
Listing 6: WorldModel.java mit Commit 7
public final class WorldModel {
public enum EventType { CAR_APPEARED, PERSON_APPEARED }
private ArrayList<Car> cars = new ArrayList<>();
private ArrayList<Person> persons = new ArrayList<>();
...
public void addCar(Car car) {
cars.add(car);
notify(EventType.CAR_APPEARED, car);
}
public void addPerson(Person person) {
persons.add(person);
notify(EventType.PERSON_APPEARED, person);
}
}
Listing 7: WorldParser.java mit Commit 7
public class WorldParser {
...
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
var car = findCar(data3);
car.ifPresent(value -> WorldModel.getInstance().addCar(value));
var person = findPerson(data3);
person.ifPresent(value ->
WorldModel.getInstance().addPerson(value));
}
private Optional<Car> findCar(byte[] data) {
...
}
private Optional<Person> findPerson(byte[] data) {
...
}
}
So sieht unsere bisherige Commit-Historie nun aus:
| Commit |
Commit-Message |
Code-Module |
| 7 |
US #2: Funktion "Lustige Personen" hinzufügen. |
FeatureFunnyPersons.java hinzufügen |
| 6 |
US #2: Erweitern des Parsers, um Personen zu erkennen |
WorldParser.java ändern |
| 5 |
US #2: Erweitern des Modells, um Personen darzustellen |
WorldModel.java ändern |
| 4 |
US #1: Funktion "Lustige Autos" hinzufügen. |
FeatureFunnyCars.java hinzufügen |
| 3 |
US #1: Erweitern des Parsers, um Autos zu erkennen |
WorldParser.java ändern |
| 2 |
US #1: Erweitern des Modells, um Autos darzustellen |
WorldModel.java ändern |
| 1 |
US #1: Skeleton-Code zur Weltdarstellung und -wahrnehmung hinzufügen |
WorldModel.java und WorldParser.java hinzufügen |
Betrachten wir nun die Abhängigkeitsstruktur der aktuellen Codebasis (Revision 7), um erste Einblicke in die architektonische Qualität unseres Projekts zu erhalten. Sie sieht skizziert folgendermaßen aus:
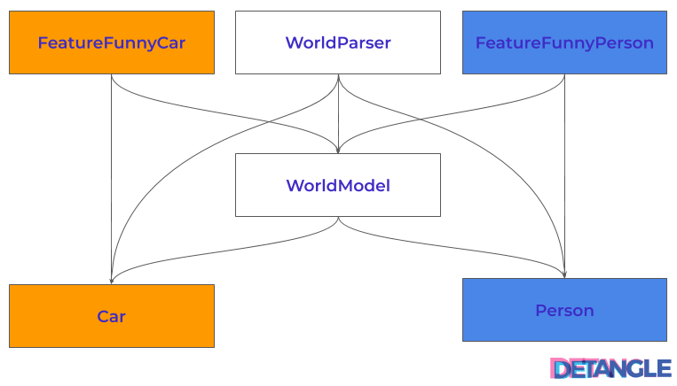
Abb. 1: Abhängigkeitsstruktur – hierarchisch strukturiert, azyklisch, aber der Schein trügt
Auf den ersten Blick sieht die modulare Struktur des Code-Beispiels recht überzeugend aus. Wir haben eine hierarchische und azyklische Abhängigkeitsstruktur erreicht. Aber an den Abhängigkeiten des WorldModel zu Car und Person deuten sich die Schwächen schon an. Ein anderes detaillierteres Bild macht die Problematik noch ersichtlicher. Die orangen Markierungen kennzeichnen die Änderungen, die aufgrund User Story #1 nötig waren, während die blauen Markierungen die Anpassungen gemäß User Story #2 darlegen: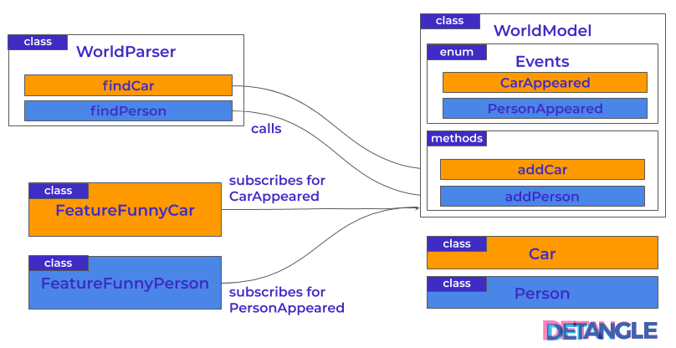 Abb. 2: Abhängigkeitsstruktur – gut, aber mit unerkannten Architektur-Hotspots
Abb. 2: Abhängigkeitsstruktur – gut, aber mit unerkannten Architektur-Hotspots
Gehen wir nun dem Umstand nach, was an dieser Architektur eher suboptimal anzusehen ist.
- Beim Hinzufügen jedes neue Features müssen wir fast alle Module in unserem System verändern.
- In der WorldParser-Klasse werden Erkennungalgorithmen für verschiedene Objekte vermischt, das Modul wird wachsen und unverständlich werden.
- In der WorldModel-Klasse ist die Situation ähnlich aber noch schlimmer, weil das Code-Modul für jedes Feature an drei unterschiedlichen Stellen verändert werden muss.
Wir können argumentieren, dass die Architektur problematisch ist aber wir sehen es nicht an der Abhängigkeitsstruktur. Die gleichzeitig nötigen Anpassungen der WorldModel– und WorldParser-Klassen im Falle weiterer Features der Art “Lustige X” werden nicht sichtbar. Daher ergibt sich die Frage: woran können wir es dann “ersehen”? Es wird anhand der Feature-Kopplung und deren Visualisierung sichtbar:
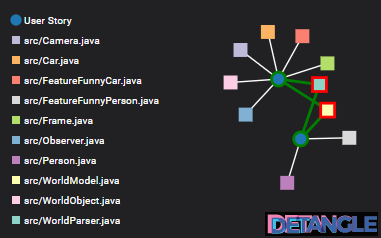
Abb. 3: Feature-Kopplung visualisieren – Architektur-Hostpots “ersehen”
Das Netzwerk-Diagramm beinhaltet blaue Kreise, die die ersten beiden User Stories darstellen. Jede User Story ist per Kante mit den Code-Modulen verbunden, die zu ihrer jeweiligen Implementierung beigetragen haben. Code-Module werden als Rechtecke visualisiert. Es wird ersichlichtlich, dass WorldModel.java und WorldParser.java als Code-Module aufgrund beider User Stories verändert wurden. Die Umsetzung einer weiteren User Story zur Erfassung eines neuen Features zur Dekoration anderer Objekttypen würde wiederum diesen beiden Code-Module anpassen. Diese beiden Code-Module weisen daher Verbindungen zu vielen gemeinsamen User Stories auf. Sie stellen rot markierte architekturelle Hotspots des Systems dar, die anhand der klassischen Abhängigkeitsgraphen nicht sichtbar werden. Diese beiden Code-Module weisen eine hohe Feature-Kopplung auf, d.h. sie tragen gemeinsam zu vielen gleichen User Stories (und dem Feature dahinter) bei.
Komplizierte Abhängigkeiten, bessere Feature-Kopplung
Nun lasst uns ein Refactoring durchführen. Die Arbeiten zum Refactoring erfassen wir als eigenes Development Requirement mit der ID #3 mit dem Titel “Refactoring zur Entkoppelung des Modells und des Parsers”. Damit gehen folgende Commit-Änderungen einher:
| Commit |
Commit-Message |
Code-Module |
| 8 |
DR #3: Refactoring Modell/Parser mittels Detector-Klassen |
WorldParser.java ändern
WorldModel.java ändern
FeatureFunnyCar.java ändern
FeatureFunnyPerson.java ändern
ObjectDetector.java hinzufügen
CarDetector.java hinzufügen
PersonDetector.java hinzufügen |
| ... |
... |
... |
| 1 |
US #1: Skeleton-Code zur Weltdarstellung und -wahrnehmung hinzufügen |
WorldModel.java und WorldParser.java hinzufügen |
Es wurde für jeden zu erkennenden Objekttyp eine eigene Detector-Klassen CarDetector und PersonDetector eingeführt, die von einer gemeinsamen abstrakten Klasse ObjectDetector abgeleitet sind. Bestehende und künftige Features (z.B. FeatureFunnyCar) zur Dekoration von Objekten instanziieren nun einen den jeweiligen ObjectDetector (z.B. CarDetector), um ihn beim Modell zu registrieren. Der jeweilige Detector erkennt das zugehörige Objekt und erzeugt das entsprechende Modell-Objekt (z.B. Car). Das folgende Diagramm skizziert die Kollaboration der Klassen nach dem Refactoring:
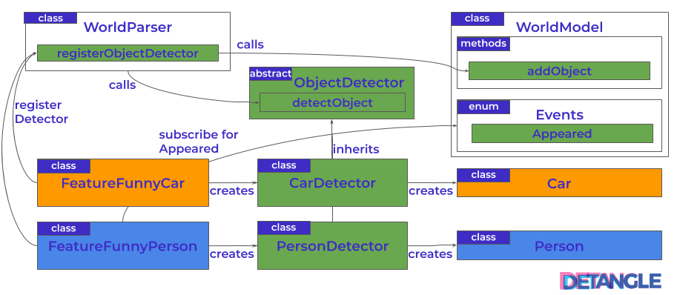 Abb. 4: Struktur der Architektur – kompliozierter aber mit kleinere Feature-Kopplung
Abb. 4: Struktur der Architektur – kompliozierter aber mit kleinere Feature-Kopplung
Der Vollständigkeit halber seien noch die revidierten Code-Stände der WorldModel und WorldParser-Klassen aufgezeigt:
Listing 8: WorldParser.java mit Commit 8
public class WorldParser {
...
private ArrayList<ObjectDetector> objectDetectors = new ArrayList<>();
public void registerObjectDetector(ObjectDetector objectDetector) {
objectDetectors.add(objectDetector);
}
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
// REMOVED
/* var car = findCar(data3);
car.ifPresent(value -> WorldModel.getInstance().addCar(value));
var person = findPerson(data3);
person.ifPresent(value ->
WorldModel.getInstance().addPerson(value));*/
for (ObjectDetector objectDetector : objectDetectors) {
var obj = objectDetector.detectObject(data3);
obj.ifPresent(value ->
WorldModel.getInstance().addObject(value));
}
}
Listing 9: WorldModel.java mit Commit 8
public final class WorldModel {
public enum EventType { APPEARED }
// REMOVED
//private ArrayList<Car>cars = new ArrayList<>();
//private ArrayList<Person> persons = new ArrayList<>();
private HashMap<EventType, List<Observer>> eventObserverMap =
new HashMap<>();
private HashMap<Class<? extends WorldObject>, ArrayList<WorldObject>>
typeObjMap= new HashMap();
...
public void addObject(WorldObject obj) {
var objList =
typeObjMap.getOrDefault(obj.getClass(), new ArrayList<>());
objList.add(obj);
typeObjMap.put(obj.getClass(), objList);
// REMOVED
/* public void addCar(Car car) {
...
}
public void addPerson(Person person) {
...
}*/
}
Es ist nun auf dem nächsten Bild eindeutig zu erkennen, dass die Abhängigkeitsstruktur komplizierter geworden ist:
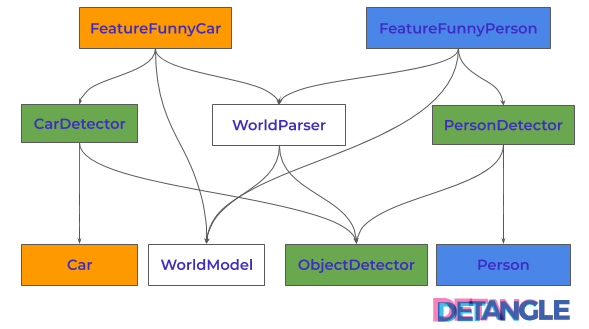
Abb. 5: Abhängigkeitsstruktur – komplizierter nach dem Refactoring
Dennoch stellt das Refactoring eine gravierende Architekturverbesserung dar, was sich beim Hinzufügen eines weiteren Features erkennbar macht. Im Netzwerk-Diagramm in Abb. 6 haben wir zwei neue User Stories aufgeführt. Darunter User Story #4: “Der Benutzer möchte vom System erkannte Gebäude lustig dekorieren (Lustige Gebäude)”) und eine entsprechende User Story zu “Lustigen Bäumen”. Es lässt sich sofort erkennen, dass die WorldModel– und WorldParser-Klassen keiner weiteren Anpassung für User Story #4 und #5 (der blaue Kreis links oben und rechts unten) bedürfen. Es werden nur neue Code-Module neu hinzugefügt wie z.B. FeatureFunnyBuildings.java, BuildingDetector.java und Building.java für User Story #4. Sie sind nun recht straightforward zu implementieren, so dass deren Listings aus Platzgründen weggelassen wurden.
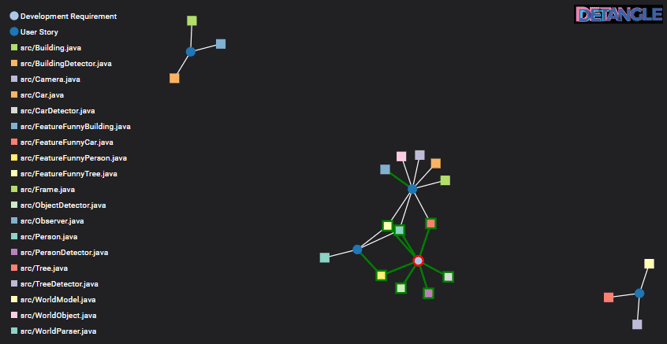 Abb. 6: Feature-Kopplung – neue Features sind nicht mehr gekoppelt
Abb. 6: Feature-Kopplung – neue Features sind nicht mehr gekoppelt
Diese neuen Code-Module weisen keine Feature-Kopplung auf, denn sie tragen zu genau einer User Story (einem Feature) bei. In dem Cluster in der Mitte haben wir auch das Development Requirement mit dem Refactoring als rot-eingerahmtes Issue markiert. Da Refactorings meistens systemübergreifend sind, wurden dafür viele der bereits bestehenden Code-Module angefasst. Daher sind Refactorings für eine Evaluierung der Feature-Kopplung natürlicherweise nicht zu berücksichtigen. Aus diesen und anderen Gründen sollten Refactorings übrigens als eigene Issues erfasst werden (siehe [3] Verbesserung der Software-Qualität durch Auswahl vernünftiger Issue-Typen).
Feature-Modularität und ihre visuellen Muster
Lasst uns nach der Ausführung des Code-Beispiels nun einen Schritt zurücktreten und wieder etwas grundsätzlicher werden. Das hehre Ziel der Softwareentwicklung besteht im Erreichen von Code-Modularität, soweit besteht weitestgehend Einigkeit. Eine bisher oft betonte Ausprägung ist die oben erwähnte Qualität der Abhängigkeitsstruktur, die sich durch eine hierarchische und azyklische Ausprägung auszeichnet. Wir haben oben die Beschränkungen dieser Sichtweise dargelegt. Eine weitere Art, Code-Modularität zu erfassen, ist sicherlich das Single Responsibility Prinzip (SRP), von dem zwei Formulierungen hier zitiert seien:
Ein Modul sollte einem, und nur einem, Akteur gegenüber verantwortlich sein
— Robert C. Martin. Clean Architecture [1]
A functional unit on a given level of abstraction should only be responsible for a single aspect of a system’s requirements. An aspect of requirements is a trait or property of requirements, which can change independently of other aspects.
— Ralf Westphal [2]
Dem Wikipedia-Eintrag zufolge geht es laut Robert C. Martin “beim SRP nicht nur um die einzelnen Klassen oder Funktionen. Vielmehr geht es um durch die Anforderungen eines Akteurs definierten Sammlungen an Funktionalitäten und Datenstrukturen.” Ralf Westphal verweist auf den ähnlichen Punkt, dass das SRP sich auf Requirements bezieht. Bisher gibt es keine allgemein akzeptierte Fassung dieses Prinzips trotz seiner intuitiv eingängigen Aussage. Ralf Westphal bezieht sich eher auf eine eigenständige Eigenschaft, die mehreren Requirements zugrunde liegt, während Robert C. Martin sich wohl eher auf einen Satz von Funktionalitäten bezieht, die auf einen Akteur/User zurückgehen.
Wir haben uns für eine pragmatische Ausprägung entschieden, die in der folgenden Formulierung besteht:
Ein Code-Modul sollte weitestgehend zu einem Requirement/einer Funktionalität/einem Feature beitragen.
— Cape of Good Code
Denn wir konnten mit Analysen zeigen, dass Code-Module, die dem zuwiderlaufen, oftmals von vielen Bugs und Wartungsaufwänden betroffen sind, wenn neue Features im Software-System in diesem Modulen hinzugefügt werden.
Die anfangs erwähnte System-Komplexität, eine Messzahl, wo im System mit wesentlich mehr Aufwand zur Feature-Umsetzung zu rechnen ist, berechnen wir mit Kennzahlen der Feature-Modularität. Die Konzepte der Feature-Kopplung und Feature-Kohäsion lassen sich wieder anhand visueller Muster im Netzwerkgraphen in Abb. 7 erklären.

Abb. 7: Feature-Modularität – visuelle Muster
Das ist ein Beispiel aus dem Apache Felix Open Source Projekt. Wiederum haben wir dunkelblaue und hellblaue Kreise (für die Issues vom Typ “Feature” und “Improvement”) und türkise Rechtecke für die Code-Module. Feature-Kohäsion misst den Beitrag einer Datei zu verschiedenen Features. Je größer die Anzahl der Features, zu denen eine Datei beiträgt, desto stärker verletzt sie das Single-Responsibility-Prinzip, und desto kleiner ist ihre Kohäsion. Im Netzwerkgraphen sind das visuelle Dreiecke, die in Abb. 7 blau markiert sind. Wir nennen dieses visuelle Muster auch “Module Tangle”. “Tangle” steht für Knäuel, Wirrwarr, was eben dieses Modul mit seinen Beiträgen zu mehreren Features/Improvements auch darstellt. Für die Weiterentwickklung dieser Module muss erhöhter kognitiver Aufwand aufgebracht werden, um unbeabsichtigte Seiteneffekte zu vermeiden.
Die Feature-Kopplung wiederum misst die Überlappung (oder Überschneidung) von Features über Dateien hinweg. Viele Module tragen gemeinsam zu vielen Features auf eine chaotische Art und Weise bei. Ein Beispiel ist in Abb. 7 als pinkes Trapez markiert. Wir bezeichnen dieses visuelle Muster als “Diamond Tangles”. Diamanten deswegen, weil dies die architekturellen Hotspots des Systems darstellen. Feature-Modularität lässt sich auch dazu nutzen, um die technischen Schulden der Features, die Feature-Qualitätsschulden, im Code zu messen. Das ist auch ein Ansatz, um an den grundsätzlichen Konflikt im Software Engineering zwischen Features und Qualität der Software anzugehen. Das soll aber in einem anderen Beitrag dargelegt werden.
Referenzen
- Robert C. Martin (2017): Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Addison-Wesley
https://www.amazon.de/Clean-Architecture-Craftsmans-Software-Structure/dp/0134494164
- Single-Responsibility-Prinzip
https://de.wikipedia.org/wiki/Single-Responsibility-Prinzip
- Konstantin Sokolov (2020). Verbesserung der Software-Qualität durch Auswahl vernünftiger Issue-Typen.
https://capeofgoodcode.com/wissen/vernuenftige-issue-typen