Für die weitere Analyse werden die eher qualitativen visuellen Eindrücke der Netzwerkdiagramme ergänzt durch die quantitative Auswertungen der Daten. Es werden dafür zwei, den jeweiligen Mustern entsprechende Indices, der Knowledge-Island-LOC-Index und den Knowledge-Balance-LOC-Index gemessen.
Knowledge-Island-LOC Index (KIL)
Das ist der prozentuale Anteil der Lines of Code (LOC) der Quellcode-Dateien, an denen genau ein:e Entwickler:in gearbeitet hat, im Vergleich zu den LOC aller Quellcode-Dateien, an denen in einem bestimmten Zeitraum generell entwickelt wurde. Die Zahl wird pro Gesamtsystem oder pro Verzeichnis gemessen.
Knowledge-Balance-LOC Index (KBL)
Das ist der prozentuale Anteil des LOC der Quellcode-Dateien, an denen genau zwei Entwickler:innen gearbeitet haben, im Vergleich zu den LOC aller Quellcode-Dateien, an denen in einem bestimmten Zeitraum generell entwickelt wurde. Dabei können pro Quellcode-Datei aus dem gleichen Verzeichnis auch unterschiedliche Paare an Entwickler:innen gearbeitet haben.
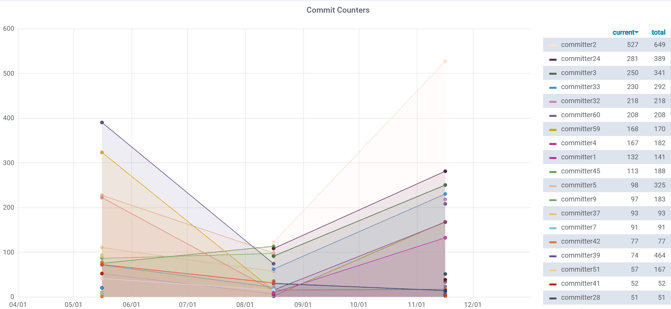
Die beiden Knowledge-Island-LOC (KIL) und Knowledge-Balance-LOC (KBL) Index-Werte ergeben zusammen einen Wert unter 1.0 (d. h. unter 100 Prozent). Das Delta zu 1.0 (100 Prozent) ergibt den LOC-Anteil an Dateien in einem Verzeichnis, an denen mindestens drei Entwickler:innen aktiv beteiligt waren. Die KIL- und KBL-Werte für die gesamte iOS-App sind nun in Abb. 7 dargestellt.
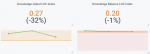
Abb. 7: Veränderung der KIL- und KBL-Werte der iOS-App von Q2 bis Q4/2020.
Daraus lassen sich die obigen Schlüsse quantitativ bestätigen:
- Der Knowledge-Island-LOC-Index beträgt 27 Prozent (ca. ¼) in Q4/2020 für die gesamte iOS-App. Dabei ist der KIL-Wert in Q4 sogar um 32 Prozent gefallen (im Vergleich zu Q3/2020), was zunächst einen guten Trend widergibt und zeigt, dass die Wissensinseln hinter der/m Hauptentwickler:in abnehmen.
- Dagegen ist der Knowledge-Balance-LOC-Index der iOS-App über das ganze Jahr 2020 auch nach dem Teamwechsel knapp über oder gleich dem kritischen Schwellenwert von 20 Prozent (ca. ⅕) geblieben. Das bedeutet, dass die in den Netzwerk-Diagrammen sichtbare Zusammenarbeit als Zweier-Teams bei weitem noch nicht ausreicht, um zumindest einen mittleren Wert von 30 Prozent oder einen guten Wert von 40 Prozent der Codebasis an Knowledge Balances für ein gutes Knowledge Sharing zu erreichen.
Im Vergleich dazu betrachten wir nun die Werte für die Android-App in Abb. 8:
- Hier ist der Knowledge-Balance-LOC-Index nach dem Teamwechsel sogar gefallen. Dieser liegt aber noch bei einem Wert von 28 Prozent. Das bedeutet, dass die Zusammenarbeit in Zweier-Teams bei Android etwas fortgeschrittener als bei iOS ist. Das deutet sich bereits beim direkten Vergleich der Netzwerk-Diagramme der iOS- und Android-Feature-Entwicklung an.
- Das bessere Bild bezüglich Knowledge Balances wird aber durch einen konstant kritischen Knowledge-Island-LOC-Index der Android-App aufgehoben. Dieser beläuft sich auf sehr hohe 57 Prozent in Q4/2020 und impliziert, dass der Koordinator bei der Android-Feature-Entwicklung weiterhin eine übergroße Wissensinsel darstellt.

Abb. 8: Veränderung der KIL- und KBL-Werte der Android-App von Q2 bis Q4/2020
7. Empfehlungen zur Verbesserung der Wissens- und Aufwandsverteilung
Selbst unter dem eingeschränkten Zugang zum SAP JIRA-Projekt und der fehlenden Möglichkeit, mit den Entwickler:innen zu kommunizieren, würden wir folgende Empfehlungen zur Verbesserung der Effektivität bei der Entwicklung neuer Features in der Corona-Warn-App aussprechen:

Tabelle 2: Empfehlungen zur Verbesserung der Wissens- und Aufwandsverteilung in der iOS- und in Android-Version der Corona-Warn-App
9. Collective Code Ownership Considered Harmful
Die KIL- und KBL-Werte mit Bezug zur Featureentwicklung lassen sich auch auf Quellcodeverzeichnisse herunterbrechen wie in Abb. 9 für Q4/2020 dargestellt. Auf der horizontalen Achse werden die KIL-Werte und auf der vertikalen Achse die KBL-Werte für Quellcode-Verzeichnisse aufgetragen. Jeder Kreis stellt ein Quellcode-Verzeichnis dar, wobei die Kreisfläche die LOC aller geänderten Quellcodedateien in dem Verzeichnis spiegelt. D. h. je größer der Kreis, desto mehr LOC machen die Quellcodedateien aus, die in dem Verzeichnis in dem betrachteten Zeitraum zur Featureentwicklung verändert wurden.
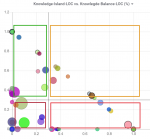
Abb. 9: Quellcode-Verzeichnisse und deren KIL- und KBL-Werte (iOS in Q4/2020)
Das Diagramm ist in folgende vier Quadranten mit jeweils unterschiedlicher Rahmenfarbe unterteilt:
Grün: Verzeichnisse, deren Knowledge-Island-Wert gering ist (unter 30 Prozent) und zusätzlich einen mittleren bis hohen Anteil (mindestens 30 Prozent) an Knowledge-Balance-Dateien aufweisen. Es handelt sich also dabei um eine sehr gute Wissensstruktur.
Gelb: Verzeichnisse, deren Knowledge-Island-Wert mittel bis hoch ist (über 30 Prozent), die aber durch einen mittleren bis hohen Anteil (mindestens 30 Prozent) an Knowledge Balances ausgeglichen werden. Diese Verzeichnisse weisen eine immer noch gute Wissensstruktur auf.
Rot (rechter Quadrant):Verzeichnisse, deren hoher Knowledge-Island-Wert nicht durch Knowledge Balances ausgeglichen wird. Hier haben wir es mit kritischen Knowledge Islands zu tun.
Dunkelrot (linker Quadrant):Verzeichnisse, an denen mindestens drei Entwickler:innen gearbeitet haben, die weder kritischen Knowledge Islands noch guten Knowledge Balances zugerechnet werden können. Diese Verzeichnisse bedürfen einer weiteren kritischen Überprüfung, wie viele Entwickler:innen tatsächlich daran gearbeitet haben, und ob es sich eher um eine “geordnete” oder “chaotische” Arbeitsweise der Entwickler:innen an gemeinsamen Quellcode-Dateien handelt.
Die Gründe, diese Verzeichnisse dennoch als dunkelrot, also als sehr kritisch anzusehen, werden mit der Betrachtung des Prinzips der “Collective Code Ownership” unten erörtert.
Diese Kategorisierung lässt sich exemplarisch an Extrembeispielen nachvollziehen. Eines davon sind die “grünen” Verzeichnisse oben links (KIL-Wert von 0, KBL-Wert von 1). Diese Kreise repräsentieren Verzeichnisse, in denen ausschließlich zu zweit entwickelt wurde. Im Gegensatz dazu stellen die Kreise rechts unten im Diagram (KIL-Wert von 1, KBL-Wert von 0) “rote”, kritische Knowledge-Island-Verzeichnisse mit einer/m einzelnen Entwickler:in dar.
Nun betrachten wir die Auswahl an Verzeichnissen, die wir bereits in unserem Blog in Bezug auf Architektur-Qualität, Dokumentation und technische Schulden als verbesserungsbedürftig ausgemacht haben [6] . Dabei handelt es sich um die Risk- und Exposure-Submission-Verzeichnisse des iOS-App-Quellcodes, die Features zur Risikobewertung und zur Handhabung von Covid-Test-Ergebnissen abdecken. Diese Verzeichnisse weisen eine globale Kopplung dieser Features auf und sollen auch aus Sicht der Wissensverteilung betrachtet werden.
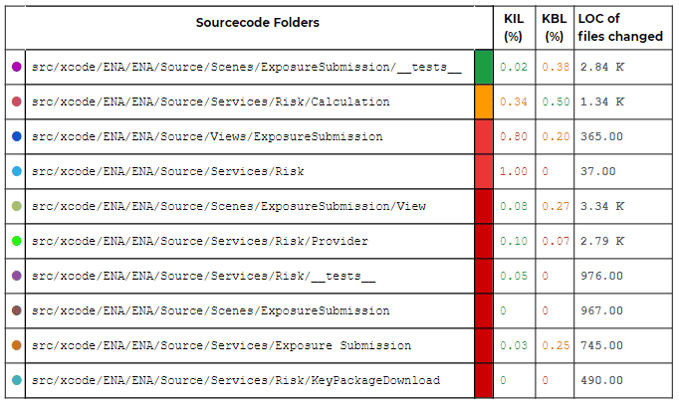 Tabelle 3: KIL- und KBL-Werte der Risk- und Exposure-Submission-Verzeichnisse und LOC der geänderten Quellcodedateien in Q4/2020
Tabelle 3: KIL- und KBL-Werte der Risk- und Exposure-Submission-Verzeichnisse und LOC der geänderten Quellcodedateien in Q4/2020
Die Betrachtung derer Knowledge-Index-Werte lässt mehrere Schlussfolgerungen zu:
- Das Verzeichnis
⬤ src/xcode/ENA/ENA/Source/Scenes/Exposure Submission/__tests__ aus dem grünen Quadranten repräsentiert eine sehr gute Wissensstruktur mit guten Knowledge-Balance– und geringen Knowledge-Island-Anteilen.
- Im Verzeichnis
⬤ src/xcode/ENA/ENA/Source/Services/Risk/Calculation aus dem gelben Quadranten wird die Eigenschaft als Knowledge Island durch einen hohen Knowledge-Balance-LOC-Wert ausgeglichen.
- Die große Mehrzahl dieser Verzeichnisse liegt im dunkelroten Quadranten aus Abb. 9. Wir haben es hier weder mit Knowledge Islands noch Knowledge Balances zu tun. Das heißt, dass mehr als drei Entwickler:innen am Großteil der bearbeiteten Dateien beteiligt waren.
Für diese Verzeichnisse lässt sich messen, ob mehrere bis viele Entwickler:innen darin auf chaotische Art und Weise “zusammen” gearbeitet haben. Denn aus unseren Projekterfahrungen wissen wir, warum solche Quellcodeverzeichnisse kommende Wartungsaufwände “magisch” anziehen. Das sind Quellcodedateien, an denen viele Entwickler:innen immer wieder mal mehr oder mal weniger Änderungen durchführen mussten. Letztendlich tritt das “Diffusion of Responsibility”-Phänomen [7] ein, dass sich irgendwann dafür keiner mehr so richtig verantwortlich fühlt und Entwickler:innen teilweise den Durchblick verlieren, weil viele der Mit-Entwickler:innen den Code mitverändert haben.
Mittels der DETANGLE Analyse Methoden lässt sich zusätzlich der Committer-Friction-Index (CFI) dafür messen. Wir haben das Diagramm mit den Committer-Friction-Werten und der Anzahl an Entwicklern für Q4/2020 in Abb. 10 aufgetragen:
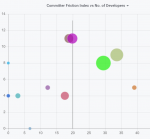
Abb. 10: CFI-Werte der Risk- und Exposure-Submission-Verzeichnisse; x-Achse: CFI, y-Achse: Anzahl Entwickler:innen
Die Betrachtung der Werte in Abb. 10 lässt folgende Beobachtungen zu:
- Am Verzeichnis
⬤ src/xcode/ENA/ENA/Source/Scenes/ExposureSubmission/__tests__ haben mit die höchste Zahl an 11 Entwickler:innen gearbeitet.Obwohl es einen hohen Knowledge-Balance-Index aufweist, liegt dessen Committer-Friction-Index dennoch im mittleren Bereich. D. h. ein Verzeichnis mit einer hohen Anzahl an Entwickler:innen kann gleichzeitig einen hohen Anteil an Quellcodedateien als Teil von Knowledge-Balances und andererseits mehrere Quelldateien aufweisen, die unstrukturiert von vielen Entwickler:innen bearbeitet wurden.
- Folgende bisher erwähnten Verzeichnisse weisen hohe Committer-Friction-Index-Werte auf:
- ⬤ src/xcode/ENA/ENA/Source/Services/Risk/Provider
- ⬤ src/xcode/ENA/ENA/Source/Scenes/ExposureSubmission/View
- ⬤ src/xcode/ENA/ENA/Source/Services/Exposure Submission
 Wir werden in diesem Artikel keine rein theoretischen Betrachtungen anstellen, sondern die deutsche Corona-Warn-App als aktuelles und relevantes Beispiel analysieren. Dabei haben wir die Wissensstrukturen der beiden iOS- und Android-Entwicklerteams Schritt für Schritt untersucht, um gute und risikobehaftete Muster wie z. B. Knowledge Balances, Knowledge Islands und Knowledge Tangles zu erkennen. Erfahrungsgemäß lassen sich die Schlüsse und Empfehlungen aus einer solchen Analyse sowohl von selbstorganisierten Softwareteams, als auch von Projektverantwortlichen für eine effektivere Zusammenarbeit und Führung nutzen.
Wir werden in diesem Artikel keine rein theoretischen Betrachtungen anstellen, sondern die deutsche Corona-Warn-App als aktuelles und relevantes Beispiel analysieren. Dabei haben wir die Wissensstrukturen der beiden iOS- und Android-Entwicklerteams Schritt für Schritt untersucht, um gute und risikobehaftete Muster wie z. B. Knowledge Balances, Knowledge Islands und Knowledge Tangles zu erkennen. Erfahrungsgemäß lassen sich die Schlüsse und Empfehlungen aus einer solchen Analyse sowohl von selbstorganisierten Softwareteams, als auch von Projektverantwortlichen für eine effektivere Zusammenarbeit und Führung nutzen.