This topic has been published as “Architektur-Hotspots aufspüren” in the 01/2020 edition of JAVAPRO. The complete article in German is available here as PDF.
Introduction
Structural dependency analyses are of limited significance. In some cases they do not capture the essential architecture hotspots, as we will show by means of a code example. The feature modularity concepts presented here are a new way of understanding system complexity. They aim at identifying architecture hotspots that increase the (maintenance) effort for new features.
A widely used approach of evaluating software systems and their architecture is the analysis of their dependency structure. The goal is to identify dependency structures that are generally known to be difficult to maintain, such as cyclic dependencies, as well as certain system-specific violations, such as cross-layer dependencies.
There is no doubt that dependency analysis provides valuable insights into the structure of a software system and can actually uncover real maintenance problems. However, despite its usefulness, classical dependency analysis has major weaknesses.
Weaknesses of Classic Dependency Analyses
Classic dependency analysis only considers structural dependencies, such as call and import dependencies. It fails to detect implicit dependencies, which means that different artifacts (e.g. files, modules, classes) have to be adapted simultaneously without a visible dependency between them.
In addition, structural dependency analysis often produces false-positive results. Even if problematic dependency structures certainly indicate potential difficulties, they do not necessarily cause real problems in terms of increased maintenance effort. The reasons for this can be different, here are a few:
- Code modules that are affected by bad dependency structures pose no stability problems and are not changed very often during the life cycle of a software system.
- The developers are aware of the potentially problematic areas and consider the effects during implementation accordingly, so that unpleasant surprises such as subsequent errors are avoided.
- Not every cyclic dependency is problematic in itself. Some may even be introduced intentionally to split large modules into smaller ones. The smaller modules are considered as part of the implementation rather than part of the architecture design.
In general, classical dependency analysis tries to detect cases of tight coupling. However, it often remains too fine-grained and short-sighted and ignores the big picture. In real systems, structural couplings between individual code modules or their absence cannot be regarded as sufficient conditions for poor or good maintainability.
There is no doubt that the presence of tight coupling is a strong indicator of maintainability problems. This insight also follows from experience. It seems, however, that the observation of structural couplings between individual code modules alone is too inaccurate. So what kind of coupling is really important in terms of maintainability?
From Module Coupling To the Idea of Feature Coupling
The answer to this question requires a definition of maintainability. A simple one could be:
The effort required to introduce new functionality into a maintainable system is roughly proportional only to the complexity of the functionality and not to the complexity of the entire system.
To put it in simple terms: In a maintainable system it should not be the case that the implementation of new functionalities, which we call features in the following, becomes more and more difficult and takes more and more time. Conversely, this means that a system should be considered maintainable regardless of the quality of its dependency structure (or possibly other metrics) as long as the average effort per feature does not increase further. Who cares about tight structural coupling and cyclic dependencies, as long as they do not slow down the entire development process? And what is a structural modularization with a nice dependency structure worth, if you constantly miss project deadlines?
We need a more accurate indicator of the potential degree of effort required to introduce new functionality into a system. And this indicator should probably best focus on the features and their implementation. Features should be treated as the main building blocks of software systems – not code modules, files or classes. We can expect that the analysis and improvement of the relationships between features, and not between code modules alone, will allow more accurate statements about the maintainability of a system.
In general, the less surrounding code needs to be understood, modified, and retested, and the less “unrelated” code responsible for other features is affected, the faster a feature can be implemented in a system. The less a feature implementation overlaps with other feature implementations and possibly “interferes” with them, the more likely it is that it can be implemented in a reasonable amount of time without affecting existing functionality.
The degree of intersection of a feature with other features in the code is here understood as feature coupling. In this context, a feature can be considered as the following:
- A human-readable description of the expected functionality, to which a unique ID is assigned.Usually , features are maintained in issue tracker systems and expressed as tickets with corresponding ticket or issue IDs.
- A set of commits to a version control system that are required to introduce the necessary code changes that make up the functionality of the feature.
To programmatically analyze feature linkage, each commit associated with a feature must be associated with the corresponding feature ID.
The ideas discussed are illustrated in the code example sketched below. For the sake of simplicity, we have specified user stories below as the ticket type to include the features.
Feature Coupling by a Code Example
In this section we will implement an example sketchily in Java. It is about recognizing objects in the real world and decorating them in a funny way. For this purpose the software has access to a rotating camera. For the first milestone the following user stories have to be implemented:
- User Story #1: The user wants to decorate cars recognized by the system in a funny way (Funny cars)
- User Story #2: The user wants to be able to decorate people recognized by the system in a funny way (Funny people)
In the following we will refer to User Story #1 as the feature “Funny cars” and User Story #2 as “Funny people”. As part of User Story #1, skeleton code is created for the representation and perception of the world. Two new files are added: WorldModel.java and WorldParser.java.
Listing 1: WorldModel.java after Commit 1
import WorldObject
import Observer
public final class WorldModel {
public enum EventType {}
private HashMap<EventType, List<Observer>>;
eventObserverMap = new HashMap<>();
public WorldModel() {
}
public void subscribe(Observer observer, EventType event) {
var observerList =
eventObserverMap.getOrDefault(event, new ArrayList<>());
observerList.add(observer);
eventObserverMap.put(event, observerList);
}
private void notify(EventType event, WorldObject obj) {
var observerList =
eventObserverMap.getOrDefault(event, new ArrayList<>());
observerList.forEach(observer ->; observer.onEvent(event, obj));
}
}
Listing 2: WorldParser.java after Commit 1
import Frame
import Camera
import WorldModel
public class WorldParser {
private Camera cam = new Camera();
public WorldParser() {
}
public void mainLoop() {
while (true) {
processFramesFor10Seconds();
cam.rotate(45);
}
}
public void processFramesFor10Seconds() {
var iterator = cam.getFrameIterator();
while (iterator.hasNext()) {
parseFrame(iterator.next());
}
}
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
}
private byte[] lowLevelProcessing1(Frame frame) {
// retrieve first-level raw data
...
}
...
}
The WorldModel class serves as a container of objects currently represented in the world and implements the Observer pattern to distribute certain events associated with those objects. The WorldParser class observes the environment by rotating the camera to detect specific objects. The next three commits implement the functionality behind User Story #1, which successively results in the following picture of the code:
Listing 3: WorldModel.java after Commit 2
public final class WorldModel {
public enum EventType { CAR_APPEARED }
private ArrayList<Car>; cars = new ArrayList<>();
...
public void addCar(Car car) {
cars.add(car);
notify(EventType.CAR_APPEARED, car);
}
}
Listing 4: WorldParser.java after Commit 3
public class WorldParser {
...
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
var car = findCar(data3);
car.ifPresent(value ->; WorldModel.getInstance().addCar(value));
}
private Optional<Car>; findCar(byte[] data) {
...
}
}
Listing 5: FeatureFunnyCar.java after Commit 4
public class FeatureFunnyCar extends Observer {
public FeatureFunnyCar() {
WorldModel.getInstance().subscribe(
this, WorldModel.EventType.CAR_APPEARED);
}
@Override
public void onEvent(WorldModel.EventType event, WorldObject obj) {
makeFunnyCar((Car)obj);
}
private void makeFunnyCar(Car car) {
...
}
}
Now User Story #2 (decorating people in a funny way) is also implemented using very similar three commits, so that in the end, in addition to the new code module FeatureFunnyPerson.java, the following picture of the code behind WorldModel.java and WorldParser.java emerges:
Listing 6: WorldModel.java after Commit 7
public final class WorldModel {
public enum EventType { CAR_APPEARED, PERSON_APPEARED }
private ArrayList<Car> cars = new ArrayList<>();
private ArrayList<Person> persons = new ArrayList<>();
...
public void addCar(Car car) {
cars.add(car);
notify(EventType.CAR_APPEARED, car);
}
public void addPerson(Person person) {
persons.add(person);
notify(EventType.PERSON_APPEARED, person);
}
}
Listing 7: WorldParser.java after Commit 7
public class WorldParser {
...
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
var car = findCar(data3);
car.ifPresent(value ->; WorldModel.getInstance().addCar(value));
var person = findPerson(data3);
person.ifPresent(value ->;
WorldModel.getInstance().addPerson(value));
}
private Optiona<Car> findCar(byte[] data) {
...
}
private Optional<Person> findPerson(byte[] data) {
...
}
}
This is what our commit history looks like now:
| Commit |
Commit-Message |
Code-Modules |
| 7 |
US #2: Add function "Funny people |
FeatureFunnyPersons.java added |
| 6 |
US #2: Extend the parser to recognize persons |
WorldParser.java modified |
| 5 |
US #2: Extend the model to represent persons |
WorldModel.java modified |
| 4 |
US #1: Add function "Funny cars |
FeatureFunnyCars.java added |
| 3 |
US #1: Extend parser to detect cars |
WorldParser.java modified |
| 2 |
US #1: Extend the model to represent cars |
WorldModel.java modified |
| 1 |
US #1: Add skeleton code for world representation and perception |
WorldModel.java und WorldParser.java added |
Now let’s look at the dependency structure of the current codebase (commit 7) to get a first insight into the architectural quality of our project. It looks like the following sketch:
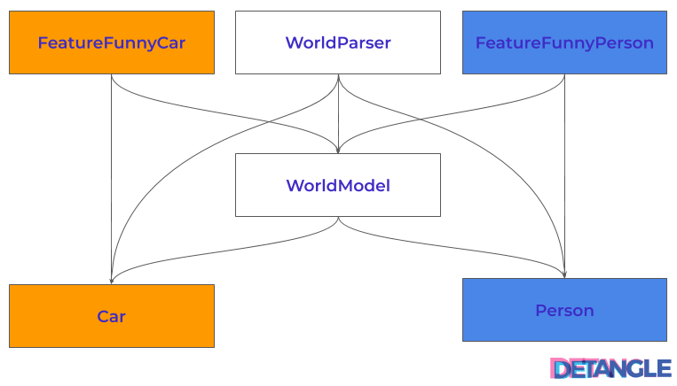 Fig. 1: Dependency structure – hierarchical, acyclic, but appearances are deceptive
Fig. 1: Dependency structure – hierarchical, acyclic, but appearances are deceptive
At first glance, the modular structure of the code example looks quite convincing. We have achieved a hierarchical and acyclic dependency structure. But the WorldModel‘s dependencies on Car and Person already indicate the weaknesses. Another more detailed picture makes the problem even more obvious. The orange markers indicate the changes that were necessary due to User Story #1, while the blue markers show the adjustments according to User Story #2:
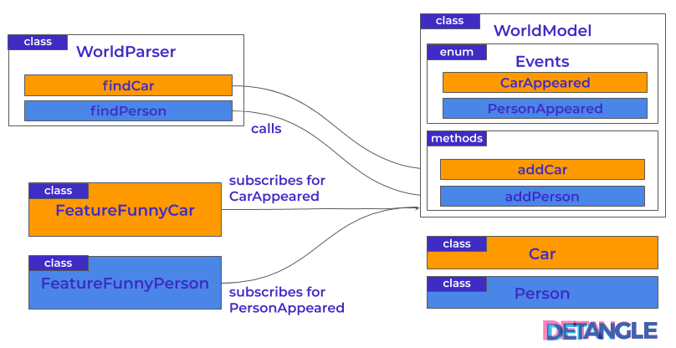 Fig. 2: Architectural structure – good, but with unrecognized architectural hotspots
Fig. 2: Architectural structure – good, but with unrecognized architectural hotspots
Let us now look at what is rather suboptimal about this architecture.
- When adding each new feature, we have to change almost every module in our system.
- In the WorldParser class, recognition algorithms for different objects are mixed, the module will grow and become incomprehensible.
- In the WorldModel class, the situation is similar but even worse, because the code module for each feature has to be changed in three different places.
We can argue that the architecture is problematic but we don’t see it in the dependency structure. The simultaneously necessary adjustments of the WorldModel and WorldParser classes in case of additional features of the “Funny X” type are not visible. Therefore the question arises: how can we “see” it then? It becomes visible through feature coupling and its visualization in Fig. 3:
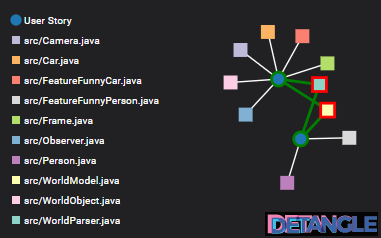
Fig. 3: Visualizing feature coupling – “seeing” architecture hostpots
The network diagram contains blue circles representing the first two user stories. Each User Story is connected by an edge to the code modules that contributed to its implementation. Code modules are visualized as rectangles. It becomes obvious that WorldModel.java and WorldParser.java have been changed as code modules based on both user stories. The implementation of another user story to capture a new feature to decorate other object types would again adapt these two code modules. These two code modules therefore have connections to many common user stories. They represent architectural hotspots of the system marked in red, which are not visible using the classic dependency graphs. These two code modules have a high feature coupling, i.e. together they contribute to many identical user stories (and the features behind them).
Complicated Dependencies, but Better Feature Coupling
Now let’s do some refactoring. We record the work on refactoring as a separate Development Requirement with ID #3 entitled “Refactoring to decouple the model and the parser”. This is accompanied by the following commit changes:
| Commit |
Commit-Message |
Code-Modules |
| 8 |
DR #3: Refactoring Modell/Parser by introducing detector classes |
WorldParser.java modified
WorldModel.java modified
FeatureFunnyCar.java modified
FeatureFunnyPerson.java modified
ObjectDetector.java added
CarDetector.java added
PersonDetector.java added |
| ... |
... |
... |
| 1 |
US #1: Add skeleton code for world representation and perception. |
WorldModel.java and WorldParser.java added |
For each type of object to be detected a separate detector classes CarDetector and PersonDetector were introduced, which are derived from a common abstract class ObjectDetector. Existing and future features (e.g. FeatureFunnyCar) for the decoration of objects now instantiate the respective ObjectDetector (e.g. CarDetector) to register it with the model. The respective detector recognizes the corresponding object and creates the corresponding model object (e.g. Car). The following diagram outlines the collaboration of the classes after the refactoring:
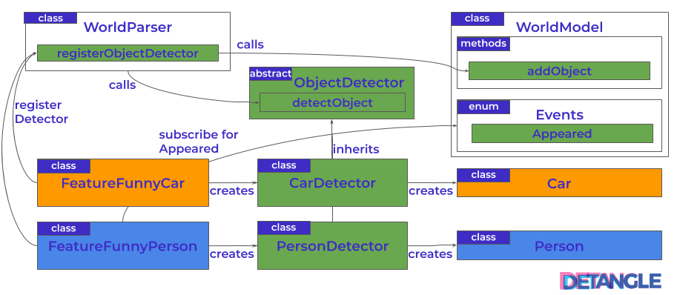 Fig. 4: Architectural structure – more complicated, but with lower feature coupling
Fig. 4: Architectural structure – more complicated, but with lower feature coupling
For the sake of completeness the revised code states of the WorldModel and WorldParser classes are shown:
Listing 8: WorldParser.java mit Commit 8
public class WorldParser {
...
private ArrayList<ObjectDetector>; objectDetectors = new ArrayList<>();
public void registerObjectDetector(ObjectDetector objectDetector) {
objectDetectors.add(objectDetector);
}
private void parseFrame(Frame frame) {
// detect concrete objects starting from data3
byte[] data1 = lowLevelProcessing1(frame);
byte[] data2 = lowLevelProcessing2(data1);
byte[] data3 = lowLevelProcessing2(data2);
// REMOVED
/* var car = findCar(data3);
car.ifPresent(value -> WorldModel.getInstance().addCar(value));
var person = findPerson(data3);
person.ifPresent(value ->
WorldModel.getInstance().addPerson(value));*/
for (ObjectDetector objectDetector : objectDetectors) {
var obj = objectDetector.detectObject(data3);
obj.ifPresent(value ->
WorldModel.getInstance().addObject(value));
}
}
Listing 9: WorldModel.java mit Commit 8
public final class WorldModel {
public enum EventType { APPEARED }
// REMOVED
//private ArrayList<Car> cars = new ArrayList<>();
//private ArrayList<Person>; persons = new ArrayList<>();
private HashMap<EventType, List<Observer>>; eventObserverMap =
new HashMap<>();
private HashMap<Class<? extends WorldObject>, ArrayList<WorldObject>>
typeObjMap = new HashMap();
...
public void addObject(WorldObject obj) {
var objList =
typeObjMap.getOrDefault(obj.getClass(), new ArrayList<>());
objList.add(obj);
typeObjMap.put(obj.getClass(), objList);
// REMOVED
/* public void addCar(Car car) {
...
}
public void addPerson(Person person) {
...
}*/
}
It is now clearly visible on the next picture that the dependency structure has become more complicated:
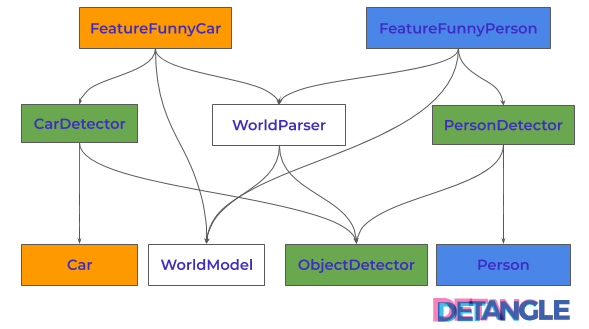
Fig. 5: Dependency structure – more complicated after the refactoring
Nevertheless, the refactoring represents a useful architectural improvement, which becomes apparent when adding another feature. The network diagram in Fig. 6 shows two new user stories. These include User Story #4: “The user wants to decorate buildings recognized by the system in a funny way (Funny Buildings)” and a corresponding User Story on “Funny Trees”. It can be seen immediately that the WorldModel and WorldParser classes do not require any further adaptation for User Story #4 and #5 (the blue circle in the upper left and lower right corner). Only new code modules are added, such as FeatureFunnyBuildings.java, BuildingDetector.java and Building.java for User Story #4, which are now quite straightforward to implement, so their listings have been omitted for space reasons.
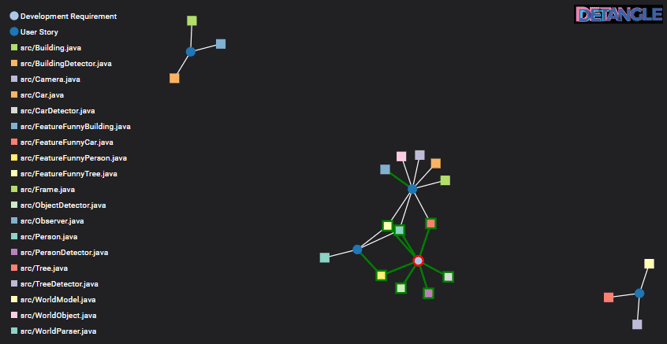 Fig. 6: Feature Coupling – the new features are not coupled any more
Fig. 6: Feature Coupling – the new features are not coupled any more
These new code modules have no feature coupling, because they contribute to exactly one user story (feature). In the cluster in the middle, we have also marked the Development Requirement with the refactoring as a red-framed issue. Since refactorings are usually cross-system, many of the existing code modules were touched for this purpose. Therefore, refactorings are naturally not to be considered for an evaluation of feature coupling. For these and other reasons, refactorings should be recorded as separate issues (see [3] Improving Software Quality by Choosing Reasonable Issue Types).
Feature Modularity and Its Visual Patterns
After presenting the code example, let’s take a step back and become more fundamental again. The noble goal of software development is to achieve code modularity, and there is broad agreement on this. A characteristic often emphasized so far is the above-mentioned quality of the dependency structure, which is characterized by a hierarchical and acyclic nature. We have explained the limitations of this view above. Another way to grasp code modularity is certainly the Single Responsibility Principle (SRP), of which two formulations are quoted here:
A module should be responsible to one, and only one, actor
— Robert C. Martin. Clean Architecture [1]
A functional unit on a given level of abstraction should only be responsible for a single aspect of a system’s requirements. An aspect of requirements is a trait or property of requirements, which can change independently of other aspects.
— Ralf Westphal [2]
According to the Wikipedia entry, and the statement from Robert C. Martin, “the SRP is not just about the individual classes or functions. Rather it is about collections of functionalities and data structures defined by the requirements of an actor”. Ralf Westphal refers to the similar point that the SRP refers to requirements. So far there is no generally accepted version of this principle despite its intuitively catchy statement. Ralf Westphal rather refers to an independent characteristic that underlies several requirements, while Robert C. Martin probably refers to a set of functionalities that can be traced back to one actor/user.
We have opted for a pragmatic approach, which consists of the following formulation:
A code module should contribute to a requirement/functionality/feature as much as possible.
— Cape of Good Code
This is because we have been able to show with analyses that code modules contrary to this are often affected by many bugs and maintenance efforts when new features are added to the software system in these modules.
The system complexity mentioned at the beginning is a measurement number where in the system much more effort is to be expected for feature implementation. We calculate with key metrics of feature modularity. The concepts of feature coupling and feature cohesion can again be explained using visual patterns in the network graph in Fig. 7.

Abb. 7: Feature modularity – visual patterns
This is an example from the Apache Felix Open Source project. Again, we have dark blue and light blue circles (for the feature and improvement issues) and turquoise rectangles for the code modules. Feature cohesion measures the contribution of a file to various features. The greater the number of features to which a file contributes, the more it violates the single-responsibility principle, and the smaller its cohesion. In the network graph, these are visual triangles that are highlighted in blue in Figure 7. We also call this visual pattern “Module Tangle”. The code modules represent tangles due to their contributions to several/many features/improvements. The further development of these modules requires increased cognitive effort to avoid unintended side effects.
Feature coupling, in turn, measures the overlap of features across files. Many modules together contribute to many features in a chaotic way. An example is marked as a pink trapezium in Figure 7. We call this visual pattern “Diamond Tangles”. Diamonds because they represent the architectural hotspots of the system. Feature modularity can also be used to measure the technical debt of features, the feature quality debt, in the code. This is also an approach to address the fundamental conflict in software engineering between features and software quality. But this will be discussed in another article.
References
- Robert C. Martin (2017): Clean Architecture: A Craftsman’s Guide to Software Structure and Design. Addison-Wesley
https://www.amazon.com/Clean-Architecture-Craftsmans-Software-Structure/dp/935286512X
- Ralf Westphal (2012). Taking the Single Responsibility Principle Seriously
https://www.developerfusion.com/article/137636/taking-the-single-responsibility-principle-seriously/
- Konstantin Sokolov (2020). Improving Software Quality by Choosing Reasonable Issue Types
https://capeofgoodcode.com/en/knowledge/reasonable-issue-types